DocLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding (Wang et al., 2023)
Samuel Adebayo

Documents vary in structure, fonts, and formats, making each type unique and meaningful in its context. Despite Document AI advancements in tasks like document layout analysis, visual information extraction, and document image classification, document AI still faces challenges with accuracy, reliability, understanding context, and adapting to new domains.
This article reviews a paper introducing the DocLLM, a lightweight extension of traditional large language models (LLMs) designed to understand visually rich documents like forms, invoices, receipts, and reports.
This model captures the document's spatial structure using textual semantics and bounding box information from optical character recognition (OCR) instead of image encoders. The researchers developed a pre-training method that learns to fill in missing text segments, helping handle varied layouts and diverse content in visual documents.
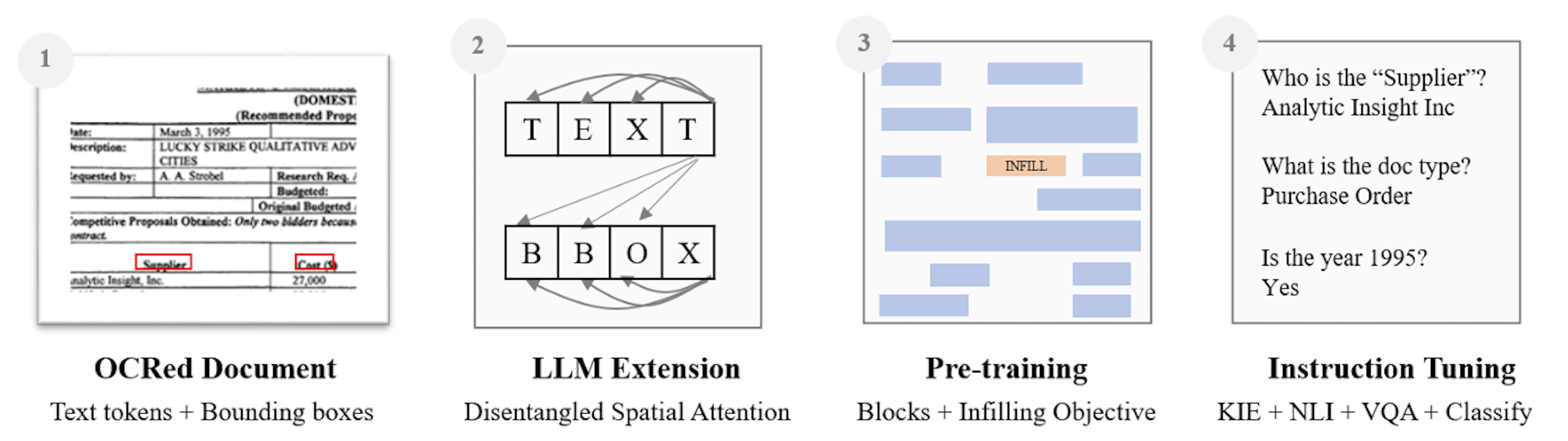
Figure 1: Key elements of DocLLM. (1) Input documents consist of text tokens and their bounding boxes. (2) The attention mechanism of LLMs now considers connections between text meaning and spatial layouts. (3) Pre-training includes infilling text blocks as an objective. (4) Task adaptation involves a new dataset of instructions. Source
Figure 1: Key elements of DocLLM. (1) Input documents consist of text tokens and their bounding boxes. (2) The attention mechanism of LLMs now considers connections between text meaning and spatial layouts. (3) Pre-training includes infilling text blocks as an objective. (4) Task adaptation involves a new dataset of instructions. Source
Definitions (Preliminary)
To facilitate reading, the authors explain key concepts to aid comprehension. They discuss the following:
Multimodal Document Understanding: The ability to comprehend and extract information from documents that contain multiple modalities or data streams, such as text content and visual layout information, such as the spatial positioning of text elements.
Spatial Layout Structure: The two-dimensional arrangement and positioning of text elements (words, phrases, sections) within a document, capturing the geometry and layout of the content.
Disentangled Attention Mechanism: This is an extension of the self-attention mechanism in transformers that computes separate attention scores for different modalities (e.g., text and spatial) and their cross-modal interactions instead of blending them into a single representation.
Infilling Pre-Training Objective: This is a self-supervised training objective in which the model learns to predict or "infill" randomly masked spans of text conditioned on the preceding and following context instead of just predicting the next token.
Self-Attention Mechanism: The core component of transformer models allows each element in a sequence to attend to other elements and capture long-range dependencies.
Autoregressive Infilling: This process generates or predicts masked or missing text segments in an autoregressive (left-to-right) manner, conditioned on the surrounding context.
Instruction Tuning: A form of transfer learning where a pre-trained language model is fine-tuned on a dataset of instructions, prompts, and expected outputs, enabling it to learn to follow instructions for various downstream tasks.
Bounding Boxes: Rectangular regions defined by coordinates (left, top, right, bottom) that enclose text elements in a document image, capturing their spatial positioning and layout geometry.
DocLLM Framework Architecture
DocLLM is built on an auto-regressive transformer language model, structured as a causal decoder (a type of decoder used in autoregressive models). It consists of stacked transformer blocks, each with a multi-head self-attention layer and a fully connected feedforward network.
Unlike standard language models, which accept only text token sequences, DocLLM is multimodal, incorporating text and visual information.
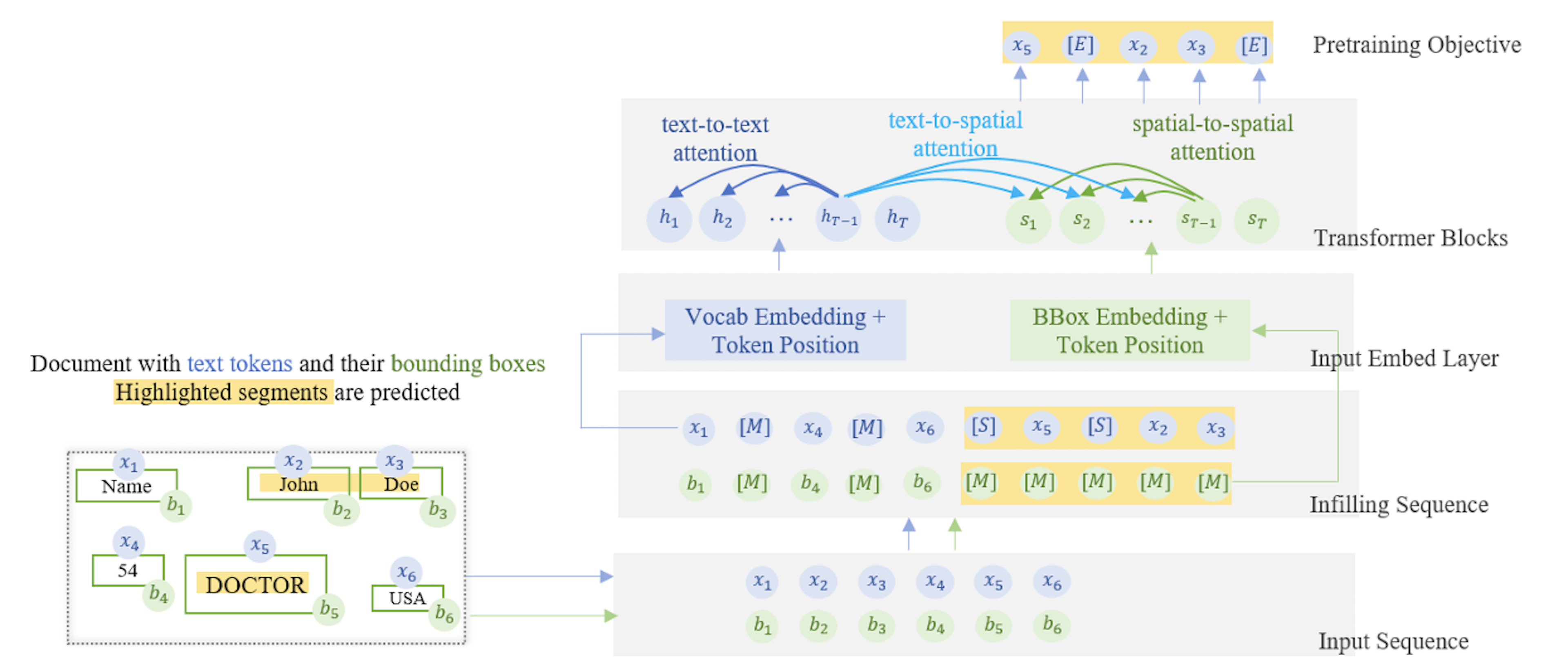
Figure 2. Shows the process DocLLM uses to incorporate text and bounding boxes for generative tasks. Source.
Figure 2. Shows the process DocLLM uses to incorporate text and bounding boxes for generative tasks. Source.
To do this, DocLLM uses a disentangled attention mechanism, autoregressive block filling, and instruction tuning on a dataset.
Preparing the Input
In this step, the model prepares the document by tokenizing text, as every natural language processing (NLP) task demands, and extracting bounding box information for location metrics.
Text Tokenization: The model begins by processing the input document through OCR if it's a scanned image or directly if it's a digital document. The text is then tokenized, which means it's broken down into manageable pieces or tokens that the model can understand.
Extracting Bounding Box Information: The model extracts bounding box information for each token and text. A bounding box is a rectangular box defined by the x and y coordinates of its corners. This step is crucial because it tells the model where each text is on the page.
Embedding
The text and spatial layouts are embedded and processed to capture the document's semantic meaning and physical positioning. This dual embedding allows the model to understand the text's content and spatial context on the page.
Creating Text Embeddings: The model creates an embedding for each text token, a dense vector representation that captures the token's semantic meaning. This process is similar to what happens in traditional language models.
Creating Spatial Embeddings: Simultaneously, the model transforms the bounding box coordinates into spatial embeddings. These embeddings are designed to capture the physical location and possibly the size of the text on the page, enabling the model to understand the document's layout.
Disentangled Spatial Attention Mechanism
At this point, each token (xi) accompanies each bounding box, bi= (left, top, right, bottom) representing its spatial location. They encode these bounding boxes into hidden vectors S to capture spatial information.
The attention mechanism score for each uni- and cross-modal interaction is calculated for the four types of interactions:
Text-to-Text (T2T) Attention: The model calculates attention scores between different text tokens, just like traditional attention mechanisms. This helps understand the contextual relationship between words or tokens.
Text-to-Spatial (T2S) Attention: Attention scores are calculated between text tokens and their corresponding spatial embeddings. This novel step allows the model to consider how the position of text on the page influences its meaning and relationship with other text elements.
Spatial-to-Spatial (S2S) Attention: The model calculates attention scores between different spatial embeddings. This process enables the model to understand the document's layout by considering how different parts are related based on their positions.
The attention scores from the T2T, T2S, and S2S calculations are combined in a “disentangled manner.” This means the model can maintain separate attention streams and then integrate them. This allows DocLLM to understand the textual content and its spatial arrangement simultaneously.
Pre-training with Infilling Objective
DocLLM undergoes initial training in a self-supervised manner using a vast collection of unlabeled documents. In this process, the model aims to predict the next token in a sequence based on the context of preceding tokens, maximizing the likelihood of correct predictions.
Masking Text Segments: Random segments of text are masked (hidden) from the model during the pre-training phase. As a result, the model must predict the masked segments using the context that the unmasked text and their spatial relationships provide.
Text Infilling: The model then attempts to fill in the masked segments. This process involves predicting the next word in a sentence and understanding the broader document context and layout to generate the missing information accurately.
Fine-Tuning with Instruction Tuning
After pre-training, the model undergoes a fine-tuning process with instruction tuning, where it's adjusted to perform specific document-understanding tasks. These could involve form extraction, question-answering based on the document content, or classifying the document type.
It excels at these tasks by using the knowledge acquired during the pre-training phase and adapting its understanding of text and layout to each task's specific requirements.
Based on the task, DocLLM generates the output, which could be extracted information from forms, answers to questions about the document, or classifications of the document type.
Experiments from the Paper
The paper evaluated DocLLM on 16 datasets across the four tasks in two experimental settings:
Same Datasets, Different Splits (SDDS) Setting: The researchers first evaluated DocLLM on an unseen test split of each of the 16 datasets composing instruction-tuning data. The goal was to check DocLLM's performance on tasks and domains that stay the same from train to test.
Same Tasks, Different Datasets (STDD) Setting: They also fine-tuned the pre-trained DocLLM model on prompts from 11 datasets and then tested it on the test sets of three other datasets. They did this to evaluate DocLLM performance on tasks that are the same but have different types of documents and layouts.
The tasks they focused on include Visual Question Answering (VQA), Knowledge Inference Extraction (KIE), and Classification (CLS), which are common in real-world applications.

Figure 3. Prompt templates used for instruction-tuning. Source.
Figure 3. Prompt templates used for instruction-tuning. Source.
As a baseline, they use Zero-Shot (ZS) prompts to compare DocLLM with other state-of-the-art LLMs of similar sizes, such as GPT-4, Llama 2, mPLUG-DocOwl, and UReader.
These prompts only include the text an OCR engine extracted from each document, excluding spatial information. Additionally, one of the evaluations includes results from recent DocAI LLMs that were assessed similarly.
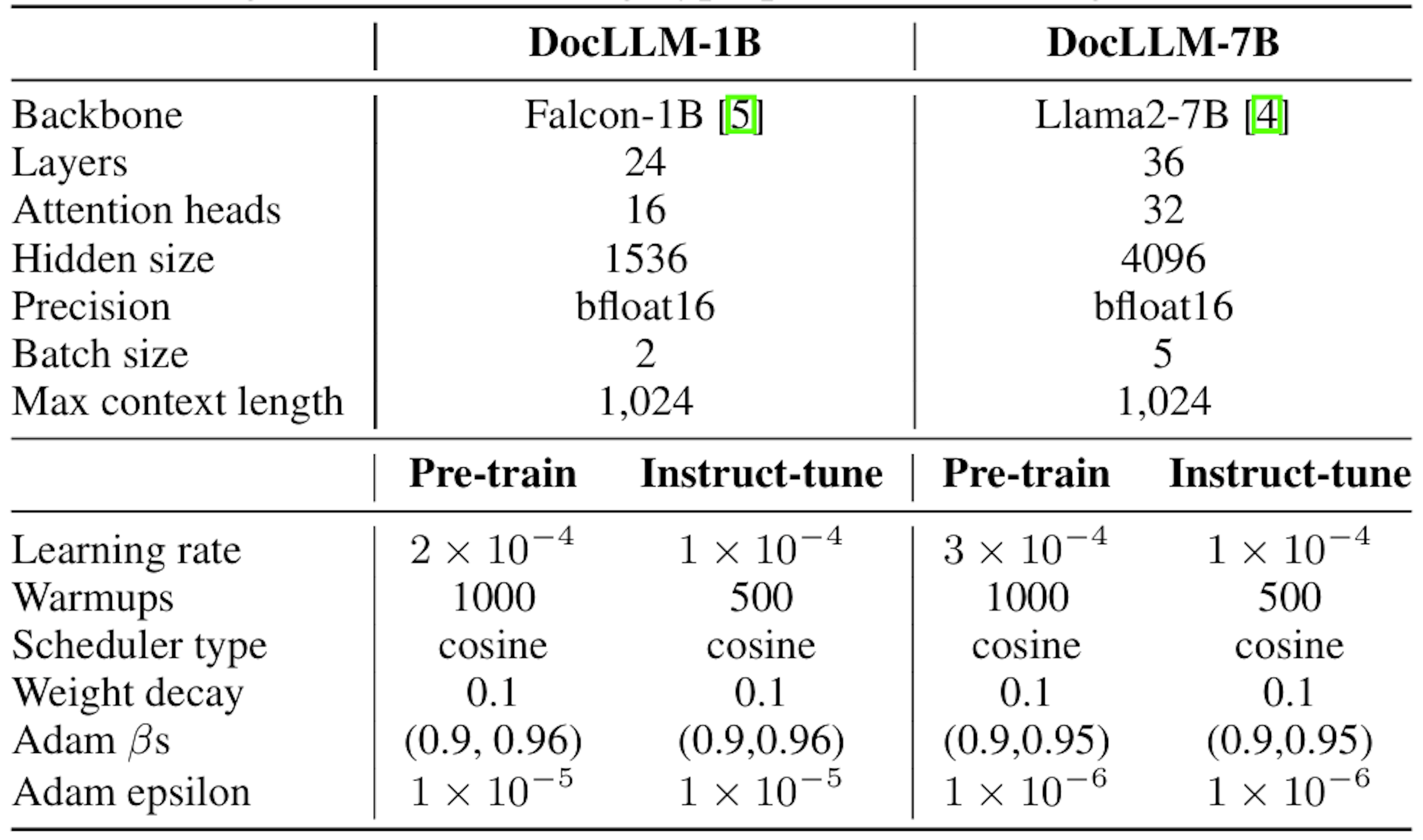
Figure 4. Model setup and training details. Source
Figure 4. Model setup and training details. Source
Metrics for evaluation
VQA Datasets: Average Normalized Levenshtein Similarity (ANLS) except Visual Machine Reading Comprehension (VisualMRC), which was evaluated with consensus-based Image Description Evaluation (CIDEr) metric, and WikiTableQuestions (WTQ) used accuracy.
CLS and NLI Dataset: Accuracy.
KIE datasets: F1 Score.
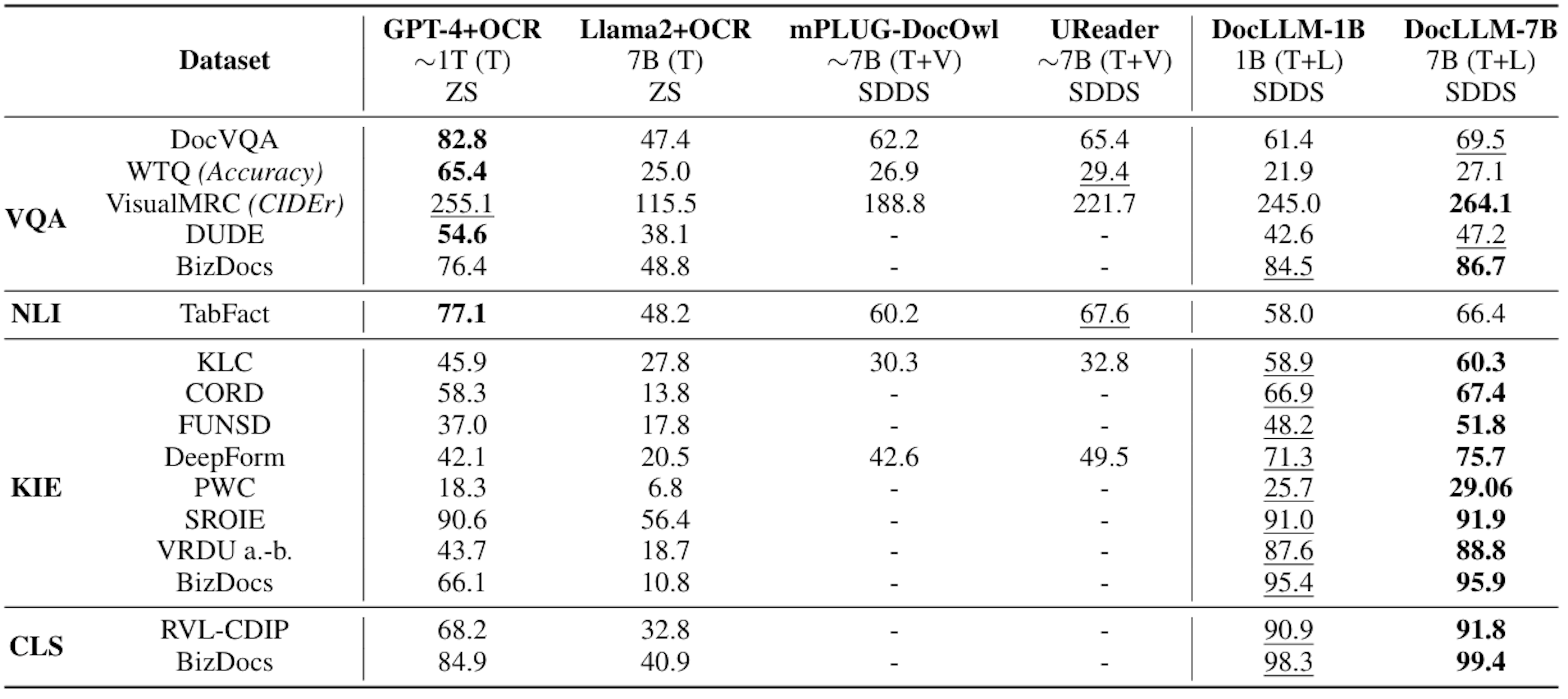
Figure 5. A table showing performance comparisons for both experiment settings. Source.
Figure 5. A table showing performance comparisons for both experiment settings. Source.
DocLLM-7B outperforms equivalent LLM baselines on 14/16 of the Same Datasets, Different Splits (SDDS), and 4/5 of the Same Tasks, Different Datasets (STDD) settings. It also performs layout-intensive tasks like key information extraction and document classification well.
Conclusions: DocLLM (A Layout-Aware Generative Language Model for Multimodal Document Understanding )
The research paper shows that the DocLLM model can effectively understand and analyze documents with lightweight visual elements like tables, shapes, etc. It does this by efficiently incorporating information about the document's layout and structure into its architecture.
The paper emphasizes that DocLLM performs better than LLMs like GPT-4 and Llama2 and can adapt to tasks involving visually complex documents. Its main contributions lie in improving document comprehension while smartly using visual layout cues without making the architecture too complex.
In future research, they aim to incorporate vision into DocLLM in a lightweight architecture.
Reference
Wang, D., Raman, N., Sibue, M., Ma, Z., Babkin, P., Kaur, S., Pei, Y., Nourbakhsh, A., & Liu, X. (2023). DocLLM: A layout-aware generative language model for multimodal document understanding. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2401.00908



