Everything you need to know about Voice AI Agents
Eteimorde Youdiowei

TL;DR
- Voice AI agents are software systems capable of communicating with users via speech. They can comprehend speech and reply with a realistic voice.
- The large language models (LLMs) and algorithms that power them enable them to reason similarly to humans. This reasoning can help them perform tasks for users.
- You can use Voice AI agents in services that require 24/7 human-like interaction, such as customer service.
- The technology behind voice AI agents comprises many domains, including speech recognition, natural language understanding, and speech synthesis.
- These systems apply deep learning algorithms, like convolutional neural networks, recurrent neural networks, and transformers. In the past, statistical algorithms like the Hidden Markov Model were employed.
Voice AI agents are sophisticated autonomous systems capable of verbal communication and performing tasks with minimal human oversight. Traditional AI tools, such as image classifiers or language models, mostly specialize in narrow tasks without the autonomy to make decisions.
Conversely, these agents process speech inputs to determine user intentions and act accordingly within their design and training (programming constraints). They combine speech recognition, decision-making algorithms, and natural language processing to perform a wide range of actions based on verbal commands.
In this article, you will learn:
Voice AI agents and how to implement them.
The role of speech recognition and synthesis in Voice AI agents.
The architecture of these systems, benchmarks, and evaluation techniques used to test their performance.
Voice AI Agents and Reinforcement Learning (RL)
Voice AI agents embody principles from reinforcement learning (RL) by refining their responses using input (user speech) and outcomes (task execution). However, their "learning" often involves more direct forms of feedback and analysis, making them distinct from RL agents that rely on reward-based learning environments.
Some voice AI agents may rely on RL algorithms to understand, improve, and adapt to user requests and changes in context for a fluid, natural interaction (rooted in automatic speech recognition).
How We Got Here: Speech Recognition, Virtual Assistants, and Voice AI Agents
Speech recognition has come a long way since the days of hidden Markov models (HMMs) and more recent deep learning methods like convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers. These changes have been very important to the progress of voice AI technology.
These developments have paved the way for voice AI agents to exceed the capabilities of early virtual assistants by offering more accurate, personalized, context-aware, and human-like interactions.
💡Voice AI agents differentiate themselves from traditional virtual assistants such as Siri and Alexa. How? They can handle complex, multi-step workflows (tasks) and provide tailored assistance to users across various domains, from customer service to healthcare. Such distinction shows how dynamic voice AI agents are in today's landscape for interactive AI systems.
Technical Foundations
Voice AI agents comprise various technologies, ranging from speech technologies that enable interaction with humans to large language models (LLMs) that power their reasoning and understanding.
In this section, you will learn the fundamentals of voice AI agents, including how they understand human speech and perform a given task, generate speech that sounds natural to the user, and leverage LLMs as their reasoning engine.
Understanding these technical foundations can help you design and build effective voice AI agents.
Here are the foundations we will look at:
Speech feature extraction.
Automatic speech recognition (ASR).
Speech synthesis.
Agents.
Algorithms.
Speech Feature Extraction
The first step in a voice AI pipeline is the feature extraction phase. In this phase, the user's voice is converted into features the speech recognition system can understand. Since speech data is initially analog, you must first convert it into a digital signal as a prerequisite for all subsequent processing steps.
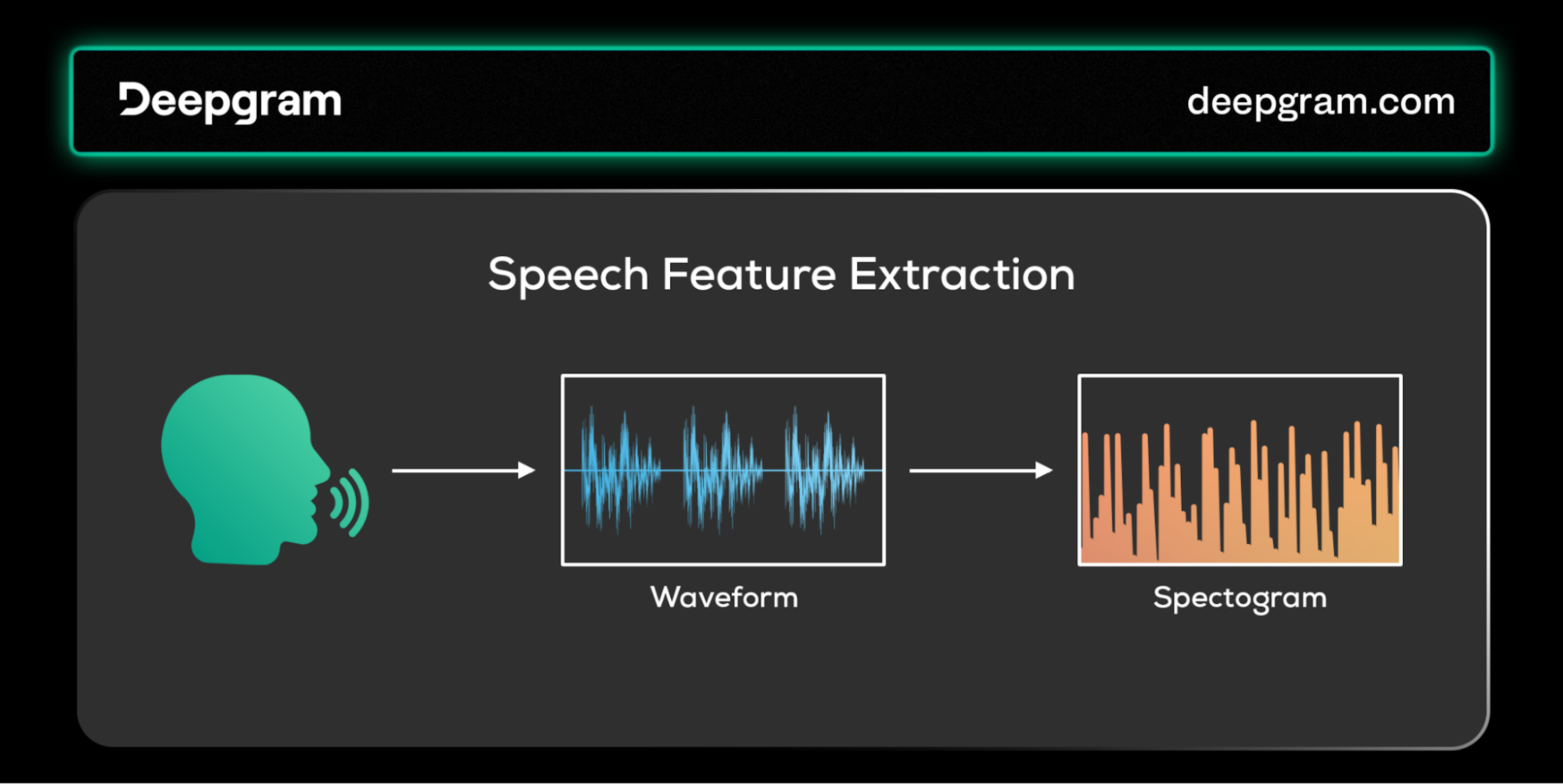
Speech feature extraction.
Speech feature extraction.
After digitization, techniques like Fast Fourier Transform (FFT) or Mel-frequency cepstral coefficients (MFCCs) can extract relevant features from the signal. This extraction process produces a spectrogram, a visual representation of the speech signal's frequency content over time.
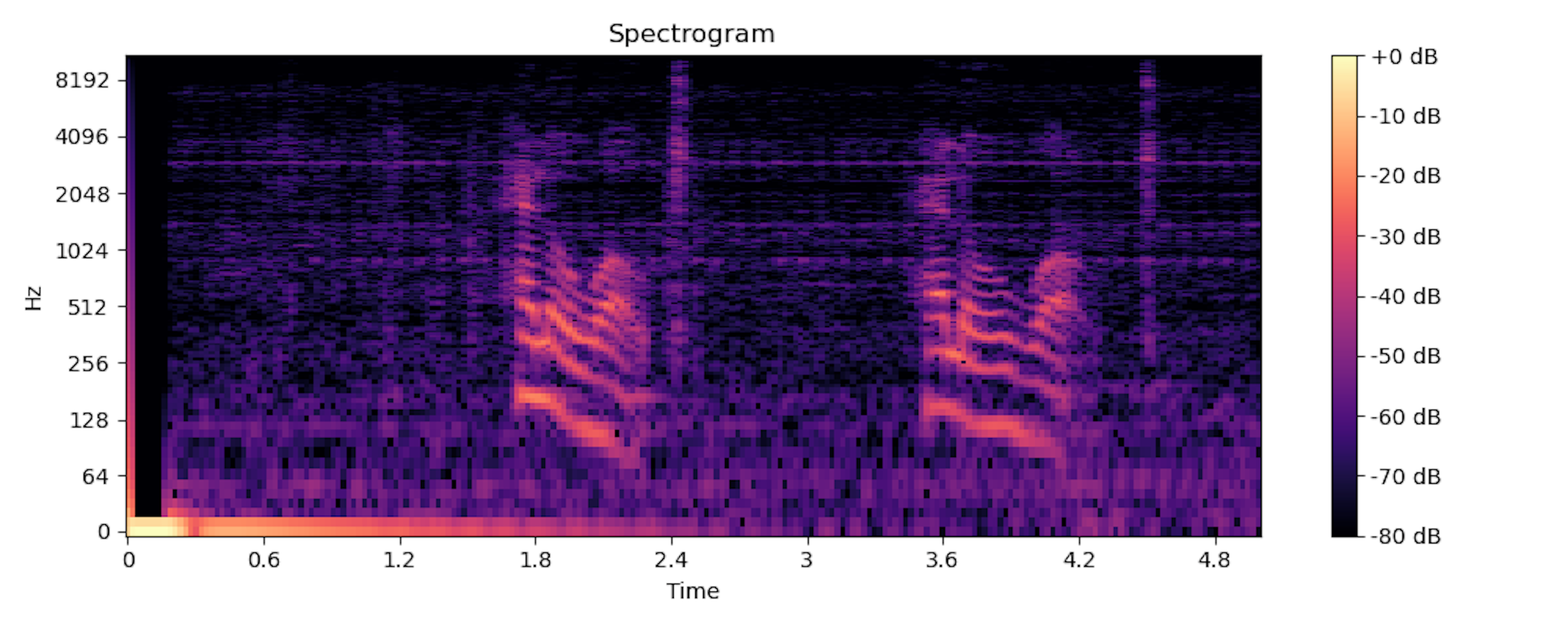
Spectrogram of human speech.
Spectrogram of human speech.
The spectrogram of speech is three-dimensional. The x-axis represents time, while the y-axis represents speech frequency. The color gradient represents the third dimension—the speech intensity level.
Automatic Speech Recognition (ASR)
Automatic Speech Recognition (ASR) or speech-to-text (STT)—like Deepgram, a transformer-based STT (shameless plug! 😆)—can convert the user's spoken words into written text. Some traditional ASR systems use an acoustic model to achieve this. The acoustic model takes the extracted spectrogram features to produce phonemes—the smallest unit of a word—that set it apart from another word.
For example, the words sat, cat, and rat differ because of their initial phonemes. Language models receive these phonemes and try to predict the text corresponding to the generated phonemes.
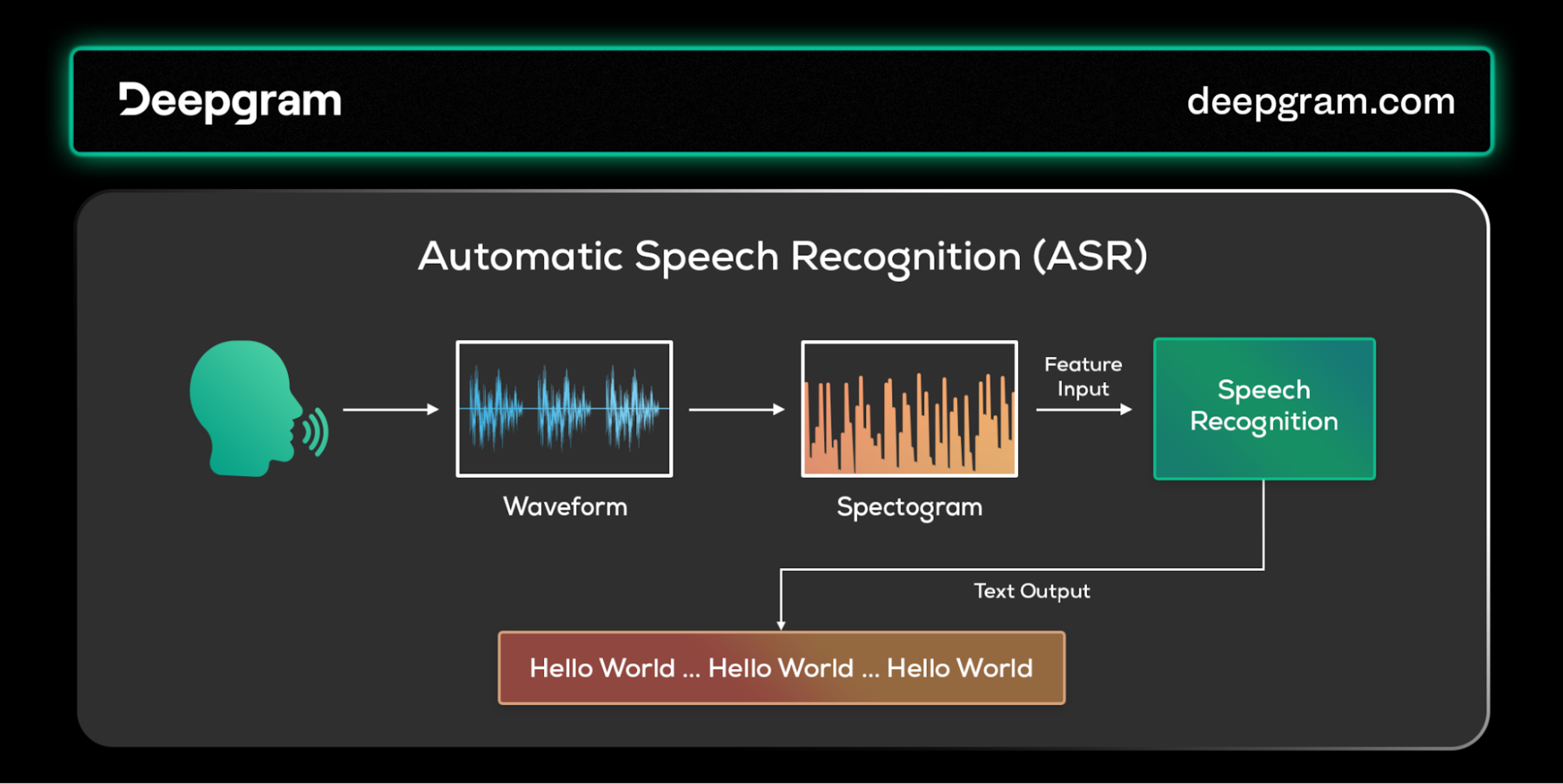
Automatic Speech Recognition (ASR) pipeline.
Automatic Speech Recognition (ASR) pipeline.
Speech recognition was initially implemented using statistical models like hidden Markov models (HMMs). Later approaches combined HMMs as the acoustic model with recurrent neural networks as the language model.
Modern ASR systems primarily employ an end-to-end deep learning approach, mostly transformer-based. (Shameless plug 😆: Deepgram is a transformer-based STT.)
💡Useful Read:
Why is deep learning the best approach for speech recognition? Check out this short article, where Sam explains why the old way of building automatic speech recognition technologies is so old.
Speech Synthesis
Converting text back into speech involves generating a phonetic sequence from the text and then synthesizing the speech. It is essentially the reverse of speech recognition, and many of the same approaches apply. A speech-generation system typically consists of two main components: language and acoustic models.
The language model converts the input text into a sequence of phonemes. The output of the language model is then fed into the acoustic model. The acoustic model can then generate the speech using one of the following methods:
Unit Selection: This approach uses pre-recorded speech units that a voice actor has recorded. These speech units can be phonemes, diphones, or entire words. The acoustic model selects speech units that best match the presented phonemes during speech generation.
Parametric Synthesis: The acoustic model generates the speech instead of selecting pre-recorded units. It does this by intelligently converting the phonemes into the corresponding acoustic features that can be represented on a spectrogram.
Generating acoustic features is challenging, as the generated speech must sound as natural and human-like as possible. To achieve this, the acoustic model must consider various factors, such as prosody, intonation, and the stress of the speech.
The acoustic model's output is then passed through a vocoder, which generates the corresponding sound waveform. The vocoder synthesizes the speech waveform based on the acoustic features generated by the acoustic model.
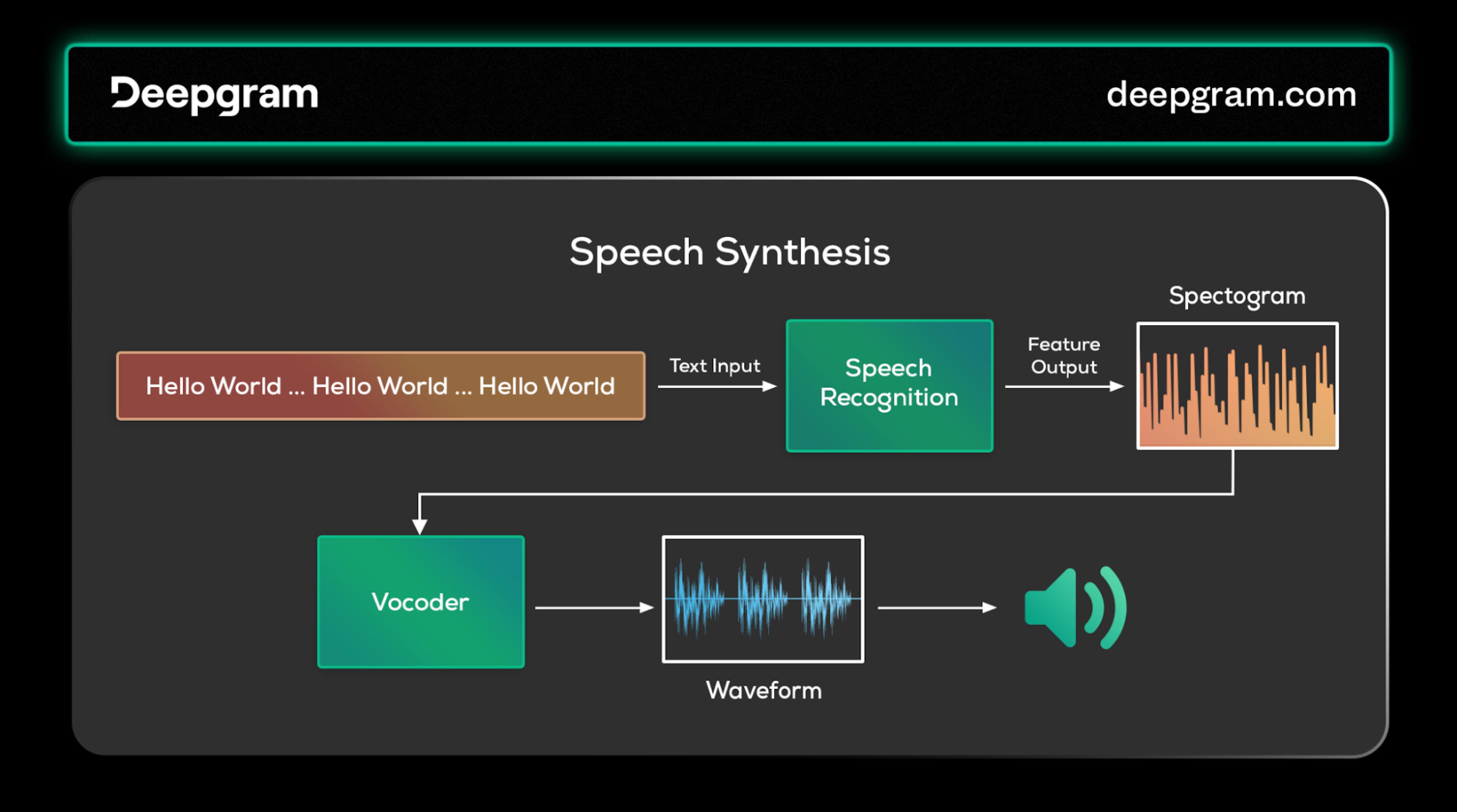
Speech synthesis pipeline.
Speech synthesis pipeline.
The quality of the generated speech depends on the accuracy and naturalness of the acoustic features generated by the acoustic model.
AI Agents
An agent is an AI system capable of performing tasks independently with little or no human assistance. It can deduce a conclusion from the user's input and then take the appropriate action. Because of their autonomous nature, these agents perceive, reason, and act within their operational environment, executing tasks of varying complexity.
Perception in Voice AI:
This component allows the agent to gather information from its environment. The type of information the agent can process depends on the modality of the underlying LLM.
Voice AI uses text and sound information, especially with multimodal models (GPT-4V or LlaVA) that can handle different data types (such as audio, images, videos, etc.). This is because unimodal LLMs, like most GPT 3.5 and Llama 2, only focus on text.
Reasoning with Context
After perception, an agent engages in reasoning and assimilates the interpreted input to formulate responses or action plans. In voice AI, this process is critical for discerning user intent and generating contextually relevant and coherent outputs.
Techniques like chain-of-thought reasoning empower these agents to navigate complex queries or tasks, simulating a more nuanced understanding and interaction capability.
Action and Interaction
The agent's action is the culmination of perception and reasoning, ranging from verbal responses to executing specific tasks. Depending on their design, voice AI agents may interact with external tools (e.g., search engines, calculators, external APIs, RAGs) or platforms to fulfill user requests or perform designated functions.
This action phase is dynamic, often involving iterative interactions between reasoning and execution until the desired outcome is achieved. Through these interactions, agents address immediate tasks and refine their understanding and response mechanisms to improve subsequent performance and the user experience.
Algorithms
This section gives a succinct overview of the various ML and statistical algorithms that voice AI agents use that contribute uniquely to the system's ability to comprehend and generate human speech.
Hidden Markov Models (HMMs)
Historically, HMMs were pivotal in modeling the sequential nature of speech, linking hidden states (phonemes) to observed acoustic features. These models excelled at capturing temporal transitions, facilitating early advancements in speech recognition.

Hidden Markov Model (HMM) for speech recognition.
Hidden Markov Model (HMM) for speech recognition.
However, their limited capacity to model complex dependencies and high-dimensional data led to the exploration of more sophisticated deep learning approaches. Regardless, understanding HMMs is fundamental for appreciating the evolution of speech recognition technology.
Convolutional Neural Networks (CNNs)
CNNs are a prominent feature extraction method used in speech recognition systems. Speech data is typically converted into spectrograms, which serve as the input for CNNs. These CNNs analyze segments of the user's speech extracted from the spectrograms for downstream tasks like classification.
Unlike traditional methods, CNNs excel at capturing both spectral and temporal patterns within speech, offering a more nuanced understanding of its intricate dynamics. This deep learning approach significantly improved speech recognition's accuracy, setting the stage for more advanced architectures.
Transformers
Transformers have set a new standard for speech recognition and synthesis with their exceptional ability to manage sequential data through self-attention mechanisms. This architecture facilitates a more nuanced understanding and generation of speech by efficiently processing the entire input sequence simultaneously, in stark contrast to the sequential processing of HMMs and CNNs.
In ASR, the transformer's encoder captures the subtleties of speech (nuanced features), and the decoder, using cross-attention, predicts the corresponding text. This architecture supports both supervised learning, with direct audio-text pairing, and self-supervised learning, as seen in models like Wave2Vec, enabling the system to learn from vast amounts of unlabeled data.
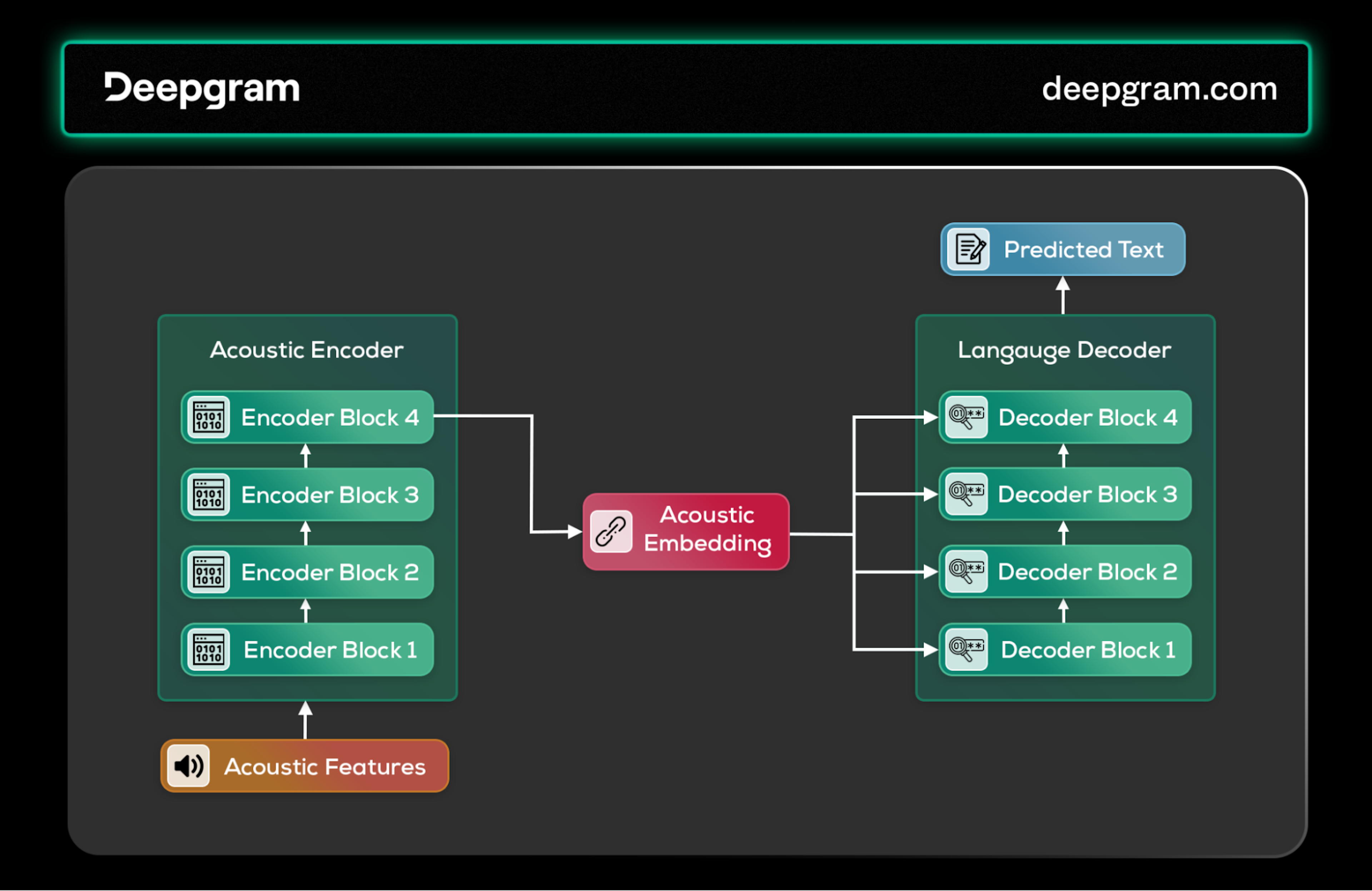
Transformers architecture for speech recognition.
Transformers architecture for speech recognition.
Transformers reverse the ASR process for speech synthesis. Text input undergoes phoneme extraction and encoding, with the acoustic decoder then generating the speech's acoustic properties. This process benefits from the transformer's ability to model complex dependencies, producing speech closely mimicking human intonation and rhythm.
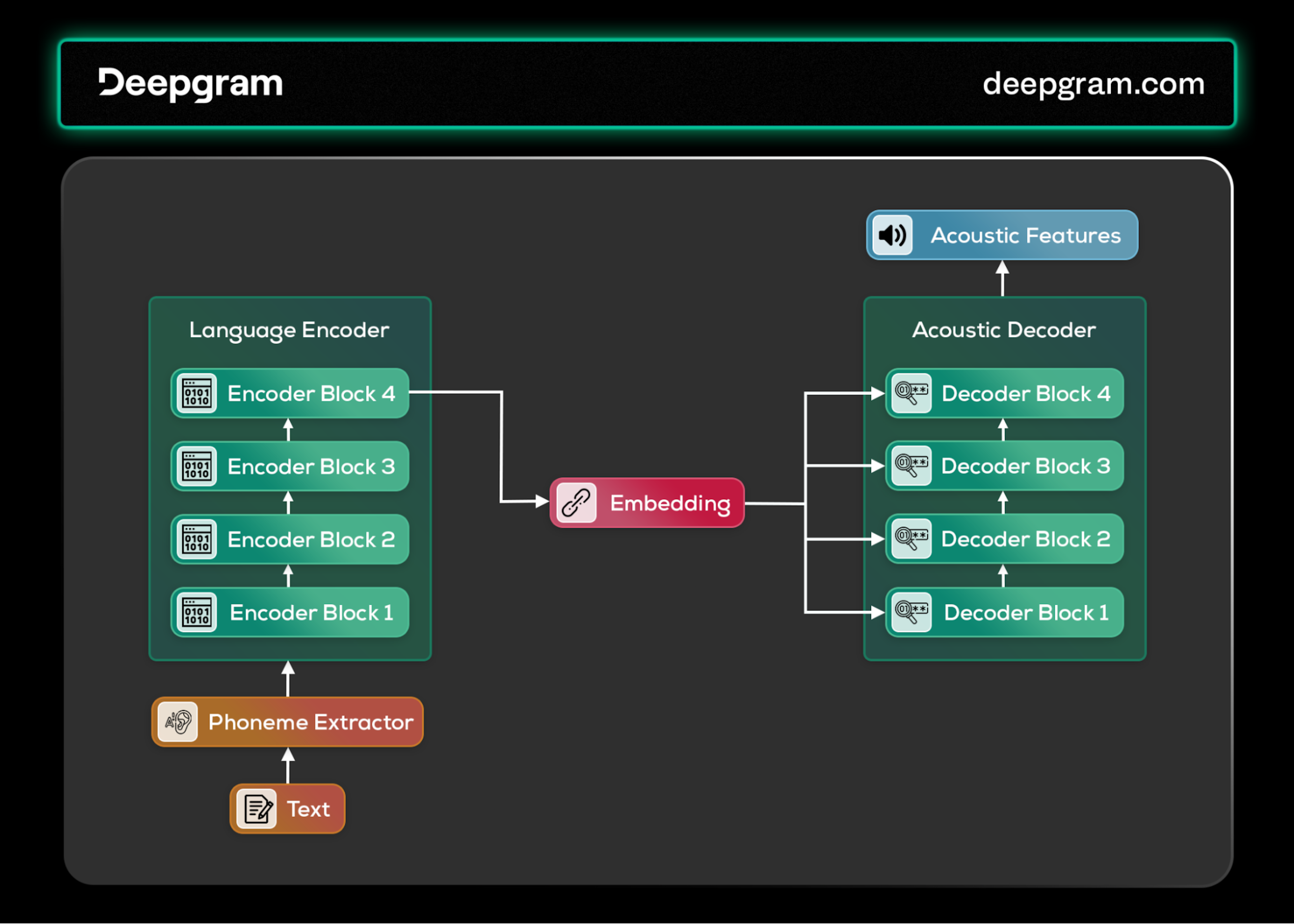
Transformers architecture for speech synthesis.
Transformers architecture for speech synthesis.
Through the development and integration of these algorithms, voice AI technologies have achieved remarkable capabilities in understanding and generating speech, underscoring their critical role in advancing human-computer interaction.
The Architecture of Voice AI Agents
Common voice AI agents adopt a client-server architecture to manage the complex processing and interaction requirements inherent to voice-based systems. This architecture is important for handling the computationally-intensive tasks of understanding and making speech sound like a person spoke it. It also allows for flexibility and scalability across a wide range of applications.
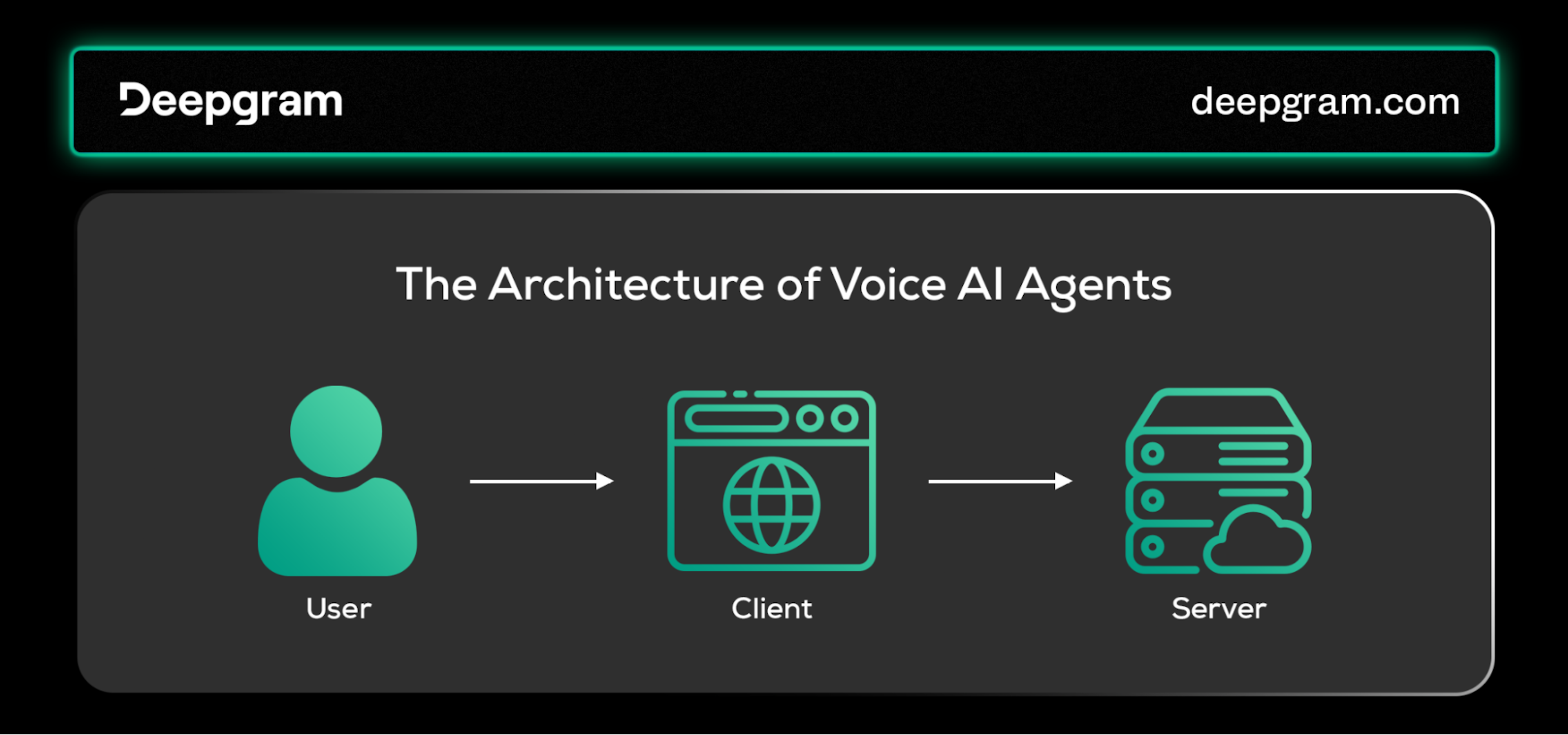
The architecture of Voice AI Agents.
The architecture of Voice AI Agents.
The Client
Clients in voice AI ecosystems vary widely, from web browsers and smartphone applications to dedicated devices like smart speakers. Each client is tailored to its context, capturing human speech and potentially other inputs (e.g., text, images) for processing.
Especially in voice-driven interactions, the client's primary function is to promptly capture and relay audio data to maintain a seamless user experience. The need for a client stems from the intensive computational demands of large models, which are impractical to run on less powerful devices.
Clients offer versatile interfacing options for tasks requiring additional input (e.g., forms, authentication).
The Server
The server is at the heart of the voice AI agent's functionality, where the core processing and intelligence reside. The server hosts key services that process and respond to user inputs. These include:
Transcription Service: Converts spoken language into text using Automatic Speech Recognition (ASR), facilitating comprehension by the system.
Model Service: This service hosts the AI agent, often powered by an LLM or a multimodal model as the cognitive engine. The agent processes text to understand user requests, plans the appropriate action, and executes them (or determines appropriate responses).
Voice Service: This service transforms textual responses into spoken words through text-to-speech (TTS) models for the system to communicate with users audibly.
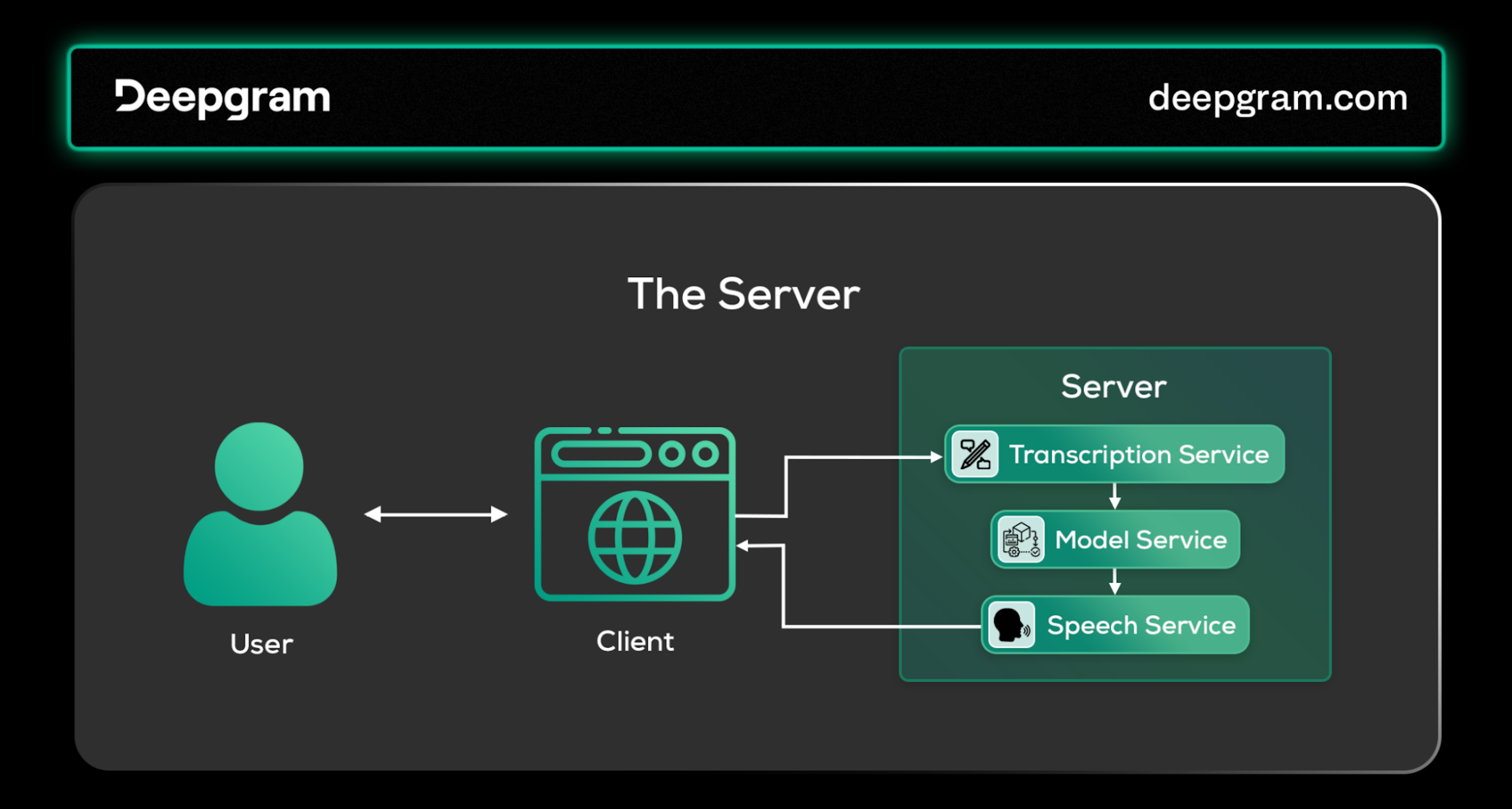
Server architecture for a Voice AI agent.
Server architecture for a Voice AI agent.
Together, these services form a pipeline that translates speech to text, derives meaning and intent, and crafts responses that are then vocalized to the user. Databases that store user data and potent computers, typically GPUs, that can handle the heavy workloads of modern AI models make these operations possible.
Common Communication Protocols
The choice of communication protocol, which must support real-time, bidirectional data exchange (full-duplex) between client and server, is critical to the seamless operation of voice AI agents. Voice-over-IP (VoIP) and WebRTC are common choices. VoIP is ideal for applications mimicking phone interactions (traditional phone services).
At the same time, WebRTC offers a real-time communication standard for browser-based applications, ensuring that voice AI agents can deliver seamless, interactive experiences across various platforms.
The selection between these protocols often depends on the application's specific requirements, such as compatibility with web browsers or mobile platforms, desired user experience, network performance, and security standards (data, encryption algorithm). The application developer decides which one to use, but the client and the server must utilize the same protocol.
Data Handling and Privacy
Managing user data within voice AI systems encompasses several critical stages, each with significant privacy and security implications. Understanding these stages is paramount to developing trustworthy and ethical voice AI solutions. Let’s break down the different ways a user's data can be kept in check.
Data Collection: Voice data, alongside ancillary information such as biometric identifiers and preferences and contextual data such as location, usage patterns, and interaction history, is collected for personalized and efficient service delivery. Clear communication about what data is collected and obtaining explicit user consent are pivotal steps in aligning with best privacy practices.
Data Processing: This phase involves transforming audio into text, filtering noise, and understanding user intent with ASR and NLP techniques. Techniques like anonymization can help mitigate privacy risks during processing without compromising the voice AI agent's functionality.
Data Storage: Various factors, such as user consent, privacy concerns, and operational needs, influence data storage decisions, such as whether to keep raw audio files or convert interactions into text. Implementing strict data lifecycle policies ensures that data is not held beyond its utility or legal requirements.
Privacy Concerns: Addressing privacy concerns involves transparently communicating data usage policies, implementing robust access controls, and ensuring user data is not misused or improperly shared. Empowering users with control over their data, including the ability to access, rectify, or delete their information, reinforces trust and compliance with privacy norms.
Data Security Measures: Besides encryption and authentication, adopting a layered security approach—including network security, application security, and regular penetration testing—ensures comprehensive protection against unauthorized access and data breaches.
Regulatory Compliance: Voice AI systems must navigate a complex landscape of global data protection laws, including GDPR, the Privacy Act, and CCPA. Adopting a privacy-by-design approach and supporting user rights to manage their data are fundamental to achieving compliance and fostering user trust.
Performance Metrics and Evaluation
Evaluating voice AI agents involves a comprehensive set of metrics and benchmarks that assess various system components, from speech recognition accuracy to the naturalness of synthesized speech. Here's a closer look at these evaluation tools:
Objective Metrics:
Word Error Rate (WER) and its variants, Sentence Error Rate (SER) and Character Error Rate (CER), serve as fundamental indicators of an ASR system's transcription accuracy. A simple formula for WER—(Substitutions + Insertions + Deletions) / Total Words—illustrates how closely the transcribed text matches the reference speech.
Real-Time Factor (RTF) evaluates the system's ability to sync with live speech input. An RTF below 1.0 indicates performance surpassing real-time expectations, which is crucial for applications requiring instant feedback.
Mel-Cepstral Distortion (MCD) evaluates the similarity between synthesized and original speech, focusing on spectral properties. It offers an objective counterpart to subjective naturalness evaluations when comparing audio quality.
Subjective Metrics:
Naturalness captures human listeners' perceptions of speech output quality, from naturalness to intelligibility. These metrics, derived from listener ratings, are pivotal for assessing user satisfaction. Standardized listening tests involving diverse participant groups help mitigate subjectivity biases.
Mean Opinion Score (MOS) for text-to-speech models involves a group of human listeners who are given a text-to-speech sample and asked to rate it from 1 to 5, where 1 means poor performance and 5 means excellent performance.
Human Evaluation: This comprehensive assessment, through task completion rates and feedback quality, directly reflects the agent's utility and user satisfaction, serving as a critical benchmark for overall performance.
Benchmarks for Comprehensive Evaluation
Next, we will discuss the benchmarks used for evaluating voice AI systems:
GLUE: The General Language Understanding Evaluation (GLUE) benchmark measures an LLM’s understanding of various natural language tasks. Since LLMs power voice AI agents, GLUE is a perfect benchmark to test the agent's understanding of natural language tasks.
ASR-GLUE: This benchmark evaluates a speech recognition system on various tasks, including speech translation, speech emotion recognition, and more. A high evaluation of this benchmark indicates that the voice AI agent can interact effectively with people.
AgentBench: This benchmark is used to evaluate agents powered by LLMs. It was introduced in the paper "AgentBench: Evaluating LLMs as Agents." The benchmark consists of eight environments to test the agent's reasoning and decision-making skills. One is an operating system environment where the agent is given a terminal to complete tasks, and another is an e-shopping environment where the agent can make purchases in a simulated online shop.
OmniACT: This is another benchmark for testing an agent's performance when working on digital tasks. It was introduced in the paper titled "OmniACT."
LJSpeech: This benchmark evaluates text-to-speech models. It contains 24 hours of speech from a single speaker.
Challenges and Limitations of Voice AI Agents
Voice AI agents have a lot of potential and can change how we interact with computers, but that doesn’t mean they don’t come with challenges for users and developers. Here are a few challenges that they currently face:
Multilingualism: There are over 7,000 natural languages in the world. Most ASR systems are multilingual by default, but they can’t know all of them, and training an ASR system in a new language isn’t trivial. This can create a barrier between the agent and the human, who speaks a different language.
Accent: Every language has different accents, which refer to the different ways of pronouncing the language. Understanding the user's intent can be very challenging if the voice AI agent doesn't have that particular accent in its training data. This is an inherent bias since a certain group would struggle with getting coherent results with the system.
Dialects: Different dialects of a particular language are also challenges for these systems, especially if little to no data is available to train the agent on that dialect. Again, this will cause a group of people to struggle with the system.
Speech defects: Individuals with speech defects, such as stuttering, cluttering, and voice disorders, would struggle to communicate with voice AI agents, as the agents might not be trained to communicate with people with such disorders.
Continuous Learning: Languages are dynamic, ever-evolving, and change with time. AI models don’t learn on the go as humans do; they must be fine-tuned or re-trained to adapt to this dynamism continually. This is a limitation of these systems, which would be in the wild, communicating with people who are continually changing how they communicate.
How to Implement a Voice AI Agent
Now that you understand voice AI agents well, let’s look at how we can implement them on a high level. Implementing a voice AI agent isn’t that difficult since much of the technology is available; all you have to do is assemble it. We can divide our implementation into five steps.
#1 Set up an ASR model
This step involves selecting the right Automatic Speech Recognition (ASR) model for your voice AI agents. There are different options. You can use an open-source model like Whisper or even the built-in speech-to-text system on the device you wish to deploy, such as a smartphone or web browser. You can also go with hosted models like Nova-2, which provide additional functionality like diarization and timestamps.
#2 Choose your Base Model
Select an LLM that fits your agent's needs, focusing on the reasoning abilities influenced by the number of parameters, responsiveness, linguistic capabilities, and ethical considerations. Consider the model's compatibility with the intended tasks (e.g., text-based or multimodal). Balance model size and computational efficiency, aiming for a model that offers the best mix of performance and resource use.
Whether proprietary (e.g., OpenAI GPT, Mixtral proprietary models, Google’s Gemini) or open-source (e.g., Llama 2, LLaVa, Mixtral 8x7B), the model should align with your tasks, especially if those multimodal interactions are anticipated.
#3 Optimizing Your Model to Become an Agent
When you have a base model, you can transform it into an agent via prompting. This involves giving the base model instructions directly with text, giving the agent a role, and setting default behavior. Another option is to fine-tune the base model, which might involve additional data and computational resources but can result in a more tailored agent.
If you choose the prompting approach, you will decide how your agent will perform tasks. You can use the ReACT approach, which involves LLM reasoning before the agent acts. Frameworks like LangChain or LlamaIndex also have built-in agent capabilities to help with these tasks.
#4 Pick Your Text-to-Speech Model
The choice of a text-to-speech (TTS) model is critical for realizing natural and engaging voice outputs. To match the model with your application's needs, consider naturalness, clarity, expressiveness, language or accent diversity (dialect support), and computational efficiency. Integrating the TTS model with your base model seamlessly converts textual responses into spoken words, which is vital for user interactions.
Consider models like Aura or Polly that allow customization of voice attributes. Speech output quality significantly affects the user experience, making this choice pivotal for your agent's success.
#5 Deployment Strategies
Deployment might not be an issue, depending on the options you picked in the prior steps. If you use an open-source model, you must handle most of the infrastructure yourself. Like selecting the right cloud environment and deciding what type of GPU to use.
You can also run most open-source models on a CPU using inference frameworks like Llama.cpp. Google also provides Gemma lightweight models designed for smaller devices. If you are building a voice AI agent for your personal use locally, you can explore the Ollama ecosystem.
Voice AI Agents Applications
As voice AI agents become more mainstream, we are beginning to see more and more applications that utilize them or provide them as a service. Here are some voice AI applications on the market today:
Vapi: Vapi is a service that enables developers to build voice AI agents. With their API, developers can build assistants performing various tasks, such as receiving inbound calls or placing customer calls.
Skit.ai: Skit.ai provides conversational AI services that communicate with customers through various modalities. Their agents can perform tasks like calling customers to recover debts.
Yellow.ai: Yellow.ai is a platform that uses AI to automate customer interactions. It provides voice AI agents that can interact with customers in several languages.
Calldesk AI: Calldesk AI is another service that allows voice AI agents to automate phone call interactions with customers.
SignalWire: Signal Wire provides APIs to let their users build voice AI agents that can communicate with their customers.
Poly.ai: Poly.ai has a customer-first voice AI agent that can help customers complete transactions, answer questions, route their calls, and more.
Daily: Daily provides toolkits to help developers easily build voice and video-powered AI applications. These toolkits can be useful in building voice AI agents.
While the services mentioned above introduce new ways of interacting with voice AI agents, virtual assistants deserve special mention as a prevalent subset.
Siri: Pioneering the mainstream adoption of voice assistants, Siri allows iPhone users to perform hands-free tasks. In the future, we can expect further advancements and capabilities from Siri.
Google Assistant and Gemini: As the default virtual assistant for Android phones for a significant period, Google Assistant has established itself as a familiar tool. However, in early 2024, Google announced Gemini as an alternative assistant for Android users.
Alexa: Unlike other assistants residing on user phones, Alexa by Amazon operates on its own dedicated devices. Primarily designed for home automation, Alexa controls smart home appliances and performs various tasks upon voice command.
Voice AI Agent Use Cases
Voice AI agents can be used in a variety of use cases. Here’s a brief list of the following industries they can be applied to:
Customer Service: Voice AI agents can provide automated support, answer frequently asked questions, and assist with troubleshooting in customer service. They can also help with appointment scheduling, order tracking, and other customer service tasks.
Education: Voice AI agents can provide personalized tutoring, language learning, and educational content. They can also help students with special needs, such as dyslexia or other learning disabilities.
Personal Assistance: Voice AI agents can act as personal assistants, helping users manage their daily tasks, schedules, and reminders. They can also provide information on weather, news, traffic, and other topics of interest. This can be useful for individuals who can’t support themselves, such as the sick or the elderly.
Accessibility: Voice AI agents can be particularly useful for individuals with disabilities, such as those who are visually impaired or have mobility issues. With voice commands, they can control devices, access information, and communicate with others more easily. An example of this service is known as Be My AI.
Mental Health Support: Voice AI agents can be programmed to provide mental health support to users. They can help users track their mood, provide coping strategies, and connect them with mental health professionals when needed.
Key Takeaways: Voice AI Agents
Voice AI agents are set to transform the way humans interact with machines, bringing significant changes to various sectors such as customer service, healthcare, and education. By understanding and responding to human speech in real-time, these agents will provide new insights into human behavior and streamline communication processes.
However, it is important to acknowledge that voice AI technology is still developing and possesses certain flaws and biases. These flaws and biases will have to be addressed as the technology develops.
At Deepgram, we are powering innovative voice AI applications like Humach, Vapi, and Daily across speech-to-text and text-to-speech to create the AI agent future.
To learn more, please visit our API documentation or product page to explore the details of Aura, our new text-to-speech API. Sign up now to get started and receive $200 in credits (good for more than 13 million characters’ worth of voice generation) for free!
We'd love to hear from you if you have any feedback about this post or anything else around Deepgram. Please let us know in our GitHub discussions or contact us to talk to one of our product experts for more information today.



