Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation, or RAG, is a framework that allows LLMs to extract information from external knowledge databases. We can use it to give current AI models more up-to-date information, rather than having them rely solely on training data gathered before 2021, for example. Within the umbrella of Information Retrieval tasks, RAG is poised to be a game-changer.
Introduction
Imagine Alex, a robotics researcher, consulting a generative Large Language Model (LLM) to validate his assumptions about a particular algorithm. He receives an eloquent, well-articulated response but, upon later verification, realizes it was misleading. The model, primarily dependent on ingrained datasets, had tangled facts with commonly misconstrued nuances, leading to intra-disciplinary “hallucinations.” This realization hits Alex with the crucial need for an approach in the NLP landscape—one that refines data reliability while enhancing the LLM’s vast generative capability.
Enter Retrieval Augmented Generation (RAG)! Introduced by Facebook AI, RAG is poised to be a game-changer. It fuses the strengths of both retrieval and generative models, setting new benchmarks that reach beyond those of “traditional” machine learning models.
RAG's role within LLMs shares similarities with that of a diligent scholar checking out a vast library in search of information. When confronted with a complex question, the scholar doesn't just depend on memorized information. Instead, the scholar cross-references and consults a variety of books to develop a solid, well-supported response.
Similarly, RAG doesn't merely rely on established knowledge. It actively retrieves relevant information from a wide range of external documents. This enables it to acquire a deeper understanding, enhancing its ability to generate comprehensive, accurate responses.
Conceptually, this makes a lot of sense, but how does it work?
The Mechanism Behind RAG
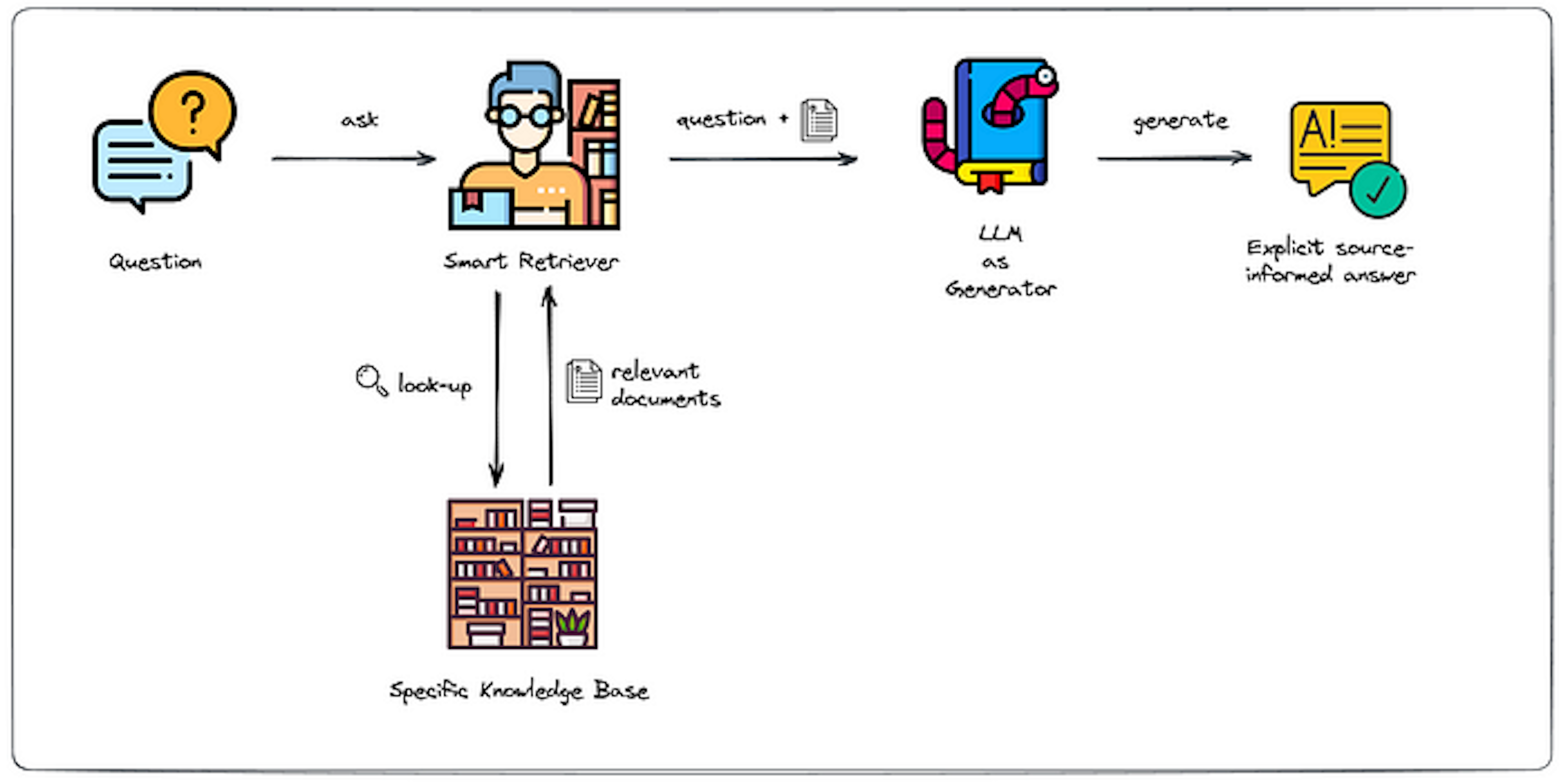
At a high level, RAG may seem like a standard question-answering system, but it houses an impressively intricate yet efficiently tuned system under its hood. RAG's main strengths are its two mechanisms—retrieval and generation—which work together to combine information and make responses that are much smarter. Its other strength is continuous learning.
Building the Vector Database
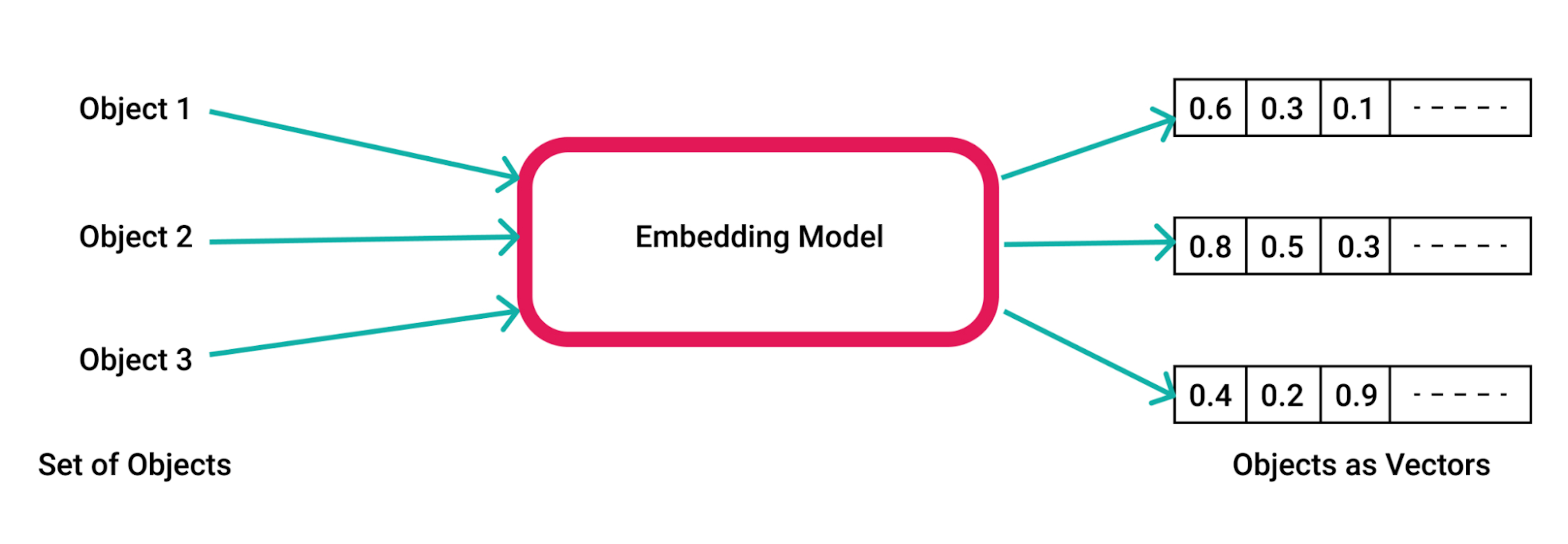
Creating relevance-based connections between many queries and the large corpus is like searching for a needle in a haystack. How can you search through thousands, if not millions, of documents quickly? RAG accomplishes this through the Dense Retrieval approach.
The Dense Retrieval approach utilizes high-dimensional vectors to store information. This method encodes words or textual data into a high-dimensional representation. The ability to learn this encoding is established during the training of the retrieval system, allowing for a nuanced and contextually rich representation of the information in the form of a vector database. This database can then be used as a highly efficient knowledge base to compare queries and document similarities.
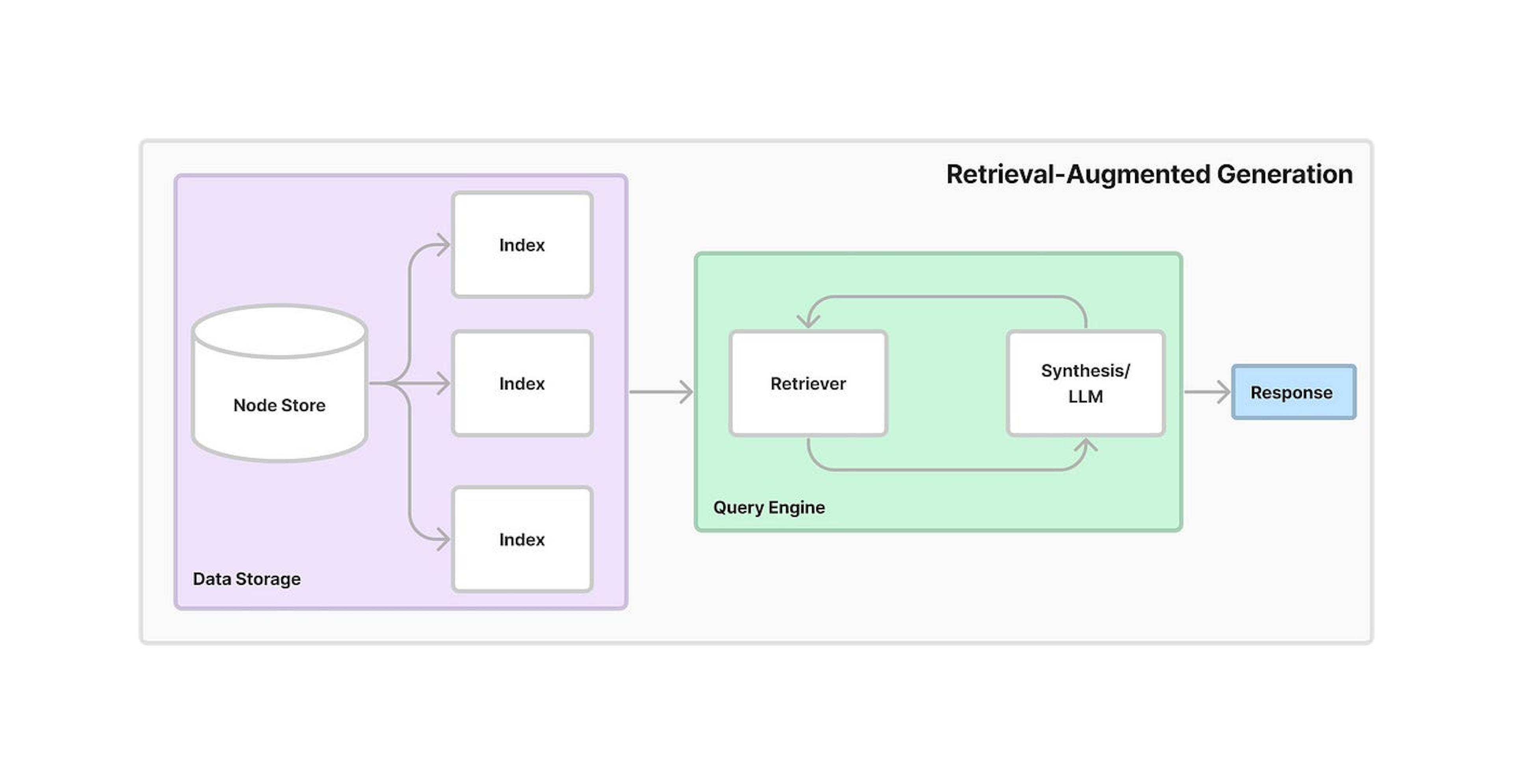
With this newly built vector database, you can put RAG into action! When you input a complex query into the system, RAG transforms the query into this encoded representation. Now that the question and documents use the same representation, RAG can compare the query's numerical vector with each document vector in the database. Vectors most relevant to the specific topic can be nominated for use in the LLM for additional context.
RAG is not just a retrieval tool; it is like an intelligent research assistant, meticulously searching your database at a speed and precision you cannot achieve with manual search.
Generation Phase
Procuring the most relevant documents was just the first part of RAG's operation—the documents it retrieves serve as an invaluable context. Retrieving the documents and corresponding query expands the knowledge base to instruct RAG's sequence-to-sequence generator in producing an informed response.
To ensure an effective fusion between the original question and the retrieved information, RAG utilizes an ML concept known as the “attention mechanism.” The “attention mechanism” allows the model to emphasize different input parts when generating each word in the response, similar to how we focus on other elements when comprehending a conversation. Information and relevance scores computed in the retrieval phase then act as a guide when generating a more well-informed response.
Comparing to Traditional Fine-Tuning Methods
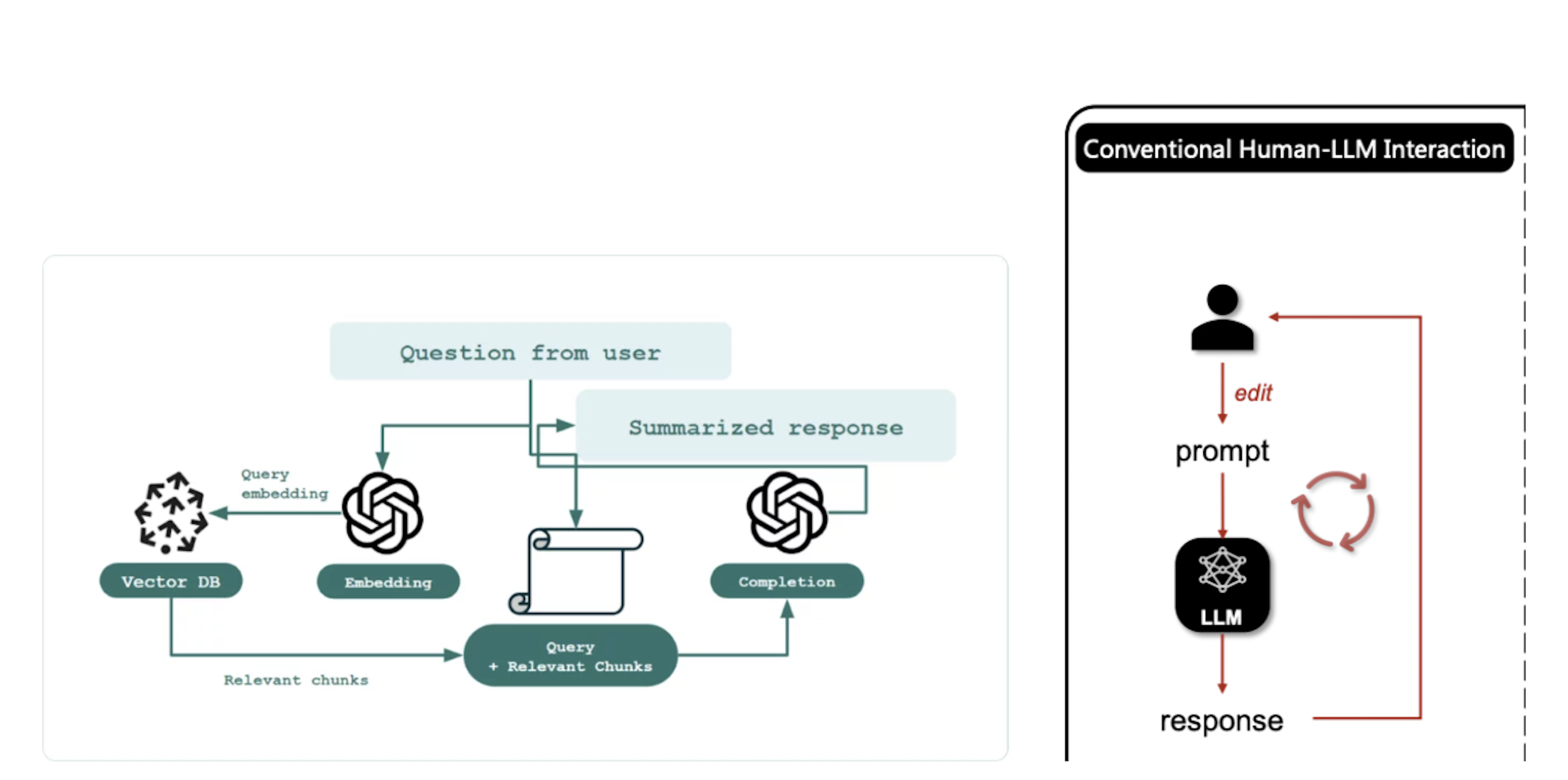
Unlike traditional language models that become static following their fine-tuning phase, RAG is an evolutionary system. It possesses the ability to progressively enhance the relevance of its responses by learning from additional external information over time.
Moreover, RAG is remarkably dynamic. It could actively fetch and integrate information from external documents during its generation phase. This dynamism adds a broader contextual understanding that produces more substantial and accurate outputs. The blend of a retrieval system and response generation model adapts the queries to the ever-evolving information landscape.
Benefits of Embracing RAG
Recognized for its versatile applicability, RAG fundamentally shifts the paradigm in NLP. RAG's cross-task compatibility replaces the conventional requirement for task-specific model training, which is frequently a resource-intensive process. With just a single fine-tuning, RAG can take on many tasks, offering considerable computational savings, which is crucial for resource-constrained applications.
Unlike traditional models that require extensive memory for numerous fine-tuned parameters, RAG maintains only a generator and shared document encoding parameters. This approach not only significantly reduces storage demands but also encourages easier deployment across devices and platforms, including those with limited memory resources.
RAG also offers a workable solution to the persistent hallucination problem, which is a common problem with LLMs where models give answers that seem plausible but are actually false. Because RAG can base its answers on retrieved documents, these kinds of mistakes are less likely to happen, which means that the outputs are more accurate.
The real-world applications of RAG are vast. It could power customer service chatbots with more accurate and context-aware responses or help academic research by finding relevant documents for thorough literature reviews.
Diving into Approaches within RAG
Multiple techniques have flourished in RAG. Noteworthy among these are:
Retrieve-then-read: In this standard approach, the RAG model retrieves relevant passages from a large text corpus, which it then synthesizes to produce a response.
Embedded Context-Enhanced Retrieval: A nuanced version of the “Retrieve-then-read” method that considers the input prompt and context before retrieval, enhancing the relevance of selected passages.
Reinforced Cross-Attention for Open-Domain Question Answering (ReACT): Designed for question-answering tasks, it uses a reinforcement learning algorithm to help the model focus more on pertinent retrieved content.
Contrastive Neural Text Generation (CoNT): Seeks to increase the accuracy and completeness of generated text under a contrastive learning framework that differentiates between machine-generated and human-written text.
Toolformer: Toolformer is a new approach to RAG that uses external tools to improve the model's performance. Toolformer can learn to use various tools, such as calculators, search engines, and translation systems.
Future explorations may involve examining various retrieval models, response generation techniques, and evaluation metrics for RAG models. RAG's evolution broadens the horizons for Natural Language Processing (NLP), promising exciting developments.
Platform Spotlight
The growing relevance of RAG in NLP has led to increased receptiveness among various platforms. Here are five leading platforms that play a crucial role in fostering RAG's development and implementation:
Facebook's ParlAI: ParlAI is a Python-based platform for enabling AI model training, validation, and testing across a multitude of dialog tasks. It houses a vast collection of datasets and has been a forerunner in leading dialogue research thanks to its comprehensive resources tailored for RAG models. It continues to stimulate RAG's evolution in complex dialog systems.
Hugging Face Transformers: Hugging Face Hub hosts thousands of pre-trained models, including RAG. The Hugging Face Transformers library provides access to RAG models that you can integrate into various NLP applications.
Pinecone: A vector database service that merges with any stack to manage, search, and deploy vectors. While traditionally used for similar item recommendation, search, personalization, and predicting rare events, Pinecone's capabilities can extend to facilitate large-scale storage and lookup, serving as a scalable backbone for RAG models' retrieval mechanisms.
Haystack: An end-to-end framework for question-answering (QA) systems that allows developers to utilize the latest Transformer-based models like RAG. Its key strengths lie in building robust, context-aware search systems, and by supporting RAG, it enhances solutions specific to information retrieval and answer generation.
Langchain: This platform simplifies the deployment of powerful AI language models, including RAG models, by providing tools for training, deploying, and maintaining these models. Langchain also provides tools for data preparation, model monitoring, and model evaluation. These tools make it easier to develop, deploy, and manage RAG models in various applications.
Challenges and Limitations
RAG holds great promise for the future, but like any trailblazing technology, it faces a few complex hurdles.
Data Privacy
Take data privacy, for instance. Since RAG cannot differentiate between sensitive and non-sensitive documents, a risk emerges for potential breaches of privacy. But don't worry—there's a solution! Implementing robust security measures explicitly for sensitive data can create a protective shield around this issue.
Prone to Hallucination
RAG, like all LLMs, is still prone to “hallucinations,” which is when language models generate plausible yet incorrect responses. Although RAG has made strides in tackling hallucinations, it’s clear the problem persists. Here, strategies like advanced fine-tuning could be game-changers, steering RAG clear of hallucinations.
Affected by Poor Quality Data
Although RAG sounds impressive, a system is only as good as its data, and RAG is no exception. When RAG fetches misleading information from external documents, it may spit out flawed outputs. Emphasizing reliable databases and ensuring rigorous information checks is a must to provide accurate and expected results from our LLM. Remember that RAG's context has its boundaries—namely, its database.
If a query seeks information outside of this, even RAG's retriever and generator can't conjure the correct answer. So, the duty to keep data in databases high-quality and assimilate real-time web content becomes all the more critical.
All of these obstacles are by no means insurmountable. Harnessing RAG's impressive capabilities is an ongoing journey in generating dependable data-driven insights—it's worth embarking on.
Conclusion
RAG is a big step forward in the development of Large Language Models (LLMs) because it combines retrieval and generative approaches to make responses that are smart and adaptable. Its key benefits include:
Dynamic learning abilities,
Resource efficiency,
Improved accuracy, which denotes a paradigm shift in NLP.
Nevertheless, potential challenges, such as data privacy and the quality of retrieved content, need to be addressed to fully use RAG' for your LLM applications, highlighting the need for robust and diligent research practices.
Key platforms like Facebook's ParlAI, Hugging Face Transformers, Pinecone, Haystack, and Langchain are carving a niche in advancing RAG, demonstrating the model’s growing significance and viability for diverse applications.
With the rapid advancements in AI, we encourage you to delve deeper into RAG models and stay updated through our AI glossary.
Additional Resources
To learn more about RAG and LLMs, visit some of the following resources: