SuperGLUE: Understanding a Sticky Benchmark for LLMs
Zian (Andy) Wang

In the past years, the development of language models has led to many evaluation metrics being proposed. The GLUE benchmark, initially introduced in early 2019, aims to offer a single-number metric that quantifies the performance of a language model across different types of understanding tasks. But as the research of Large Language Models skyrocketed since 2020, the GLUE benchmark became rather obsolete as models surpassed non-expert human performances on the benchmark, needing a more complicated metric.
SuperGLUE, proposed in late 2019, offers a brand new set of more complex tasks, as well as a public leaderboard for evaluating language models. To this day, the leaderboard is still active with submissions and improvements.
The leaderboard contains information about each submission, as well as the scores for the subtasks included within the SuperGLUE benchmark. Its website also provides a starting toolkit for quickly evaluating models on the benchmark.
The All-in-One LLM Metric: SuperGLUE
GLUE, short for General Language Understanding Evaluation, distinguishes itself from preceding evaluation methodologies thanks to the breadth of tasks it entails. Historically, NLP deep learning models were typically designed and trained for a singular task, be it text completion, sentiment analysis, or question answering. Unlike these conventional models, today's LLMs are generally pre-trained for comprehensive language comprehension. If necessary, they are then fine-tuned to be optimally suited for specific tasks.
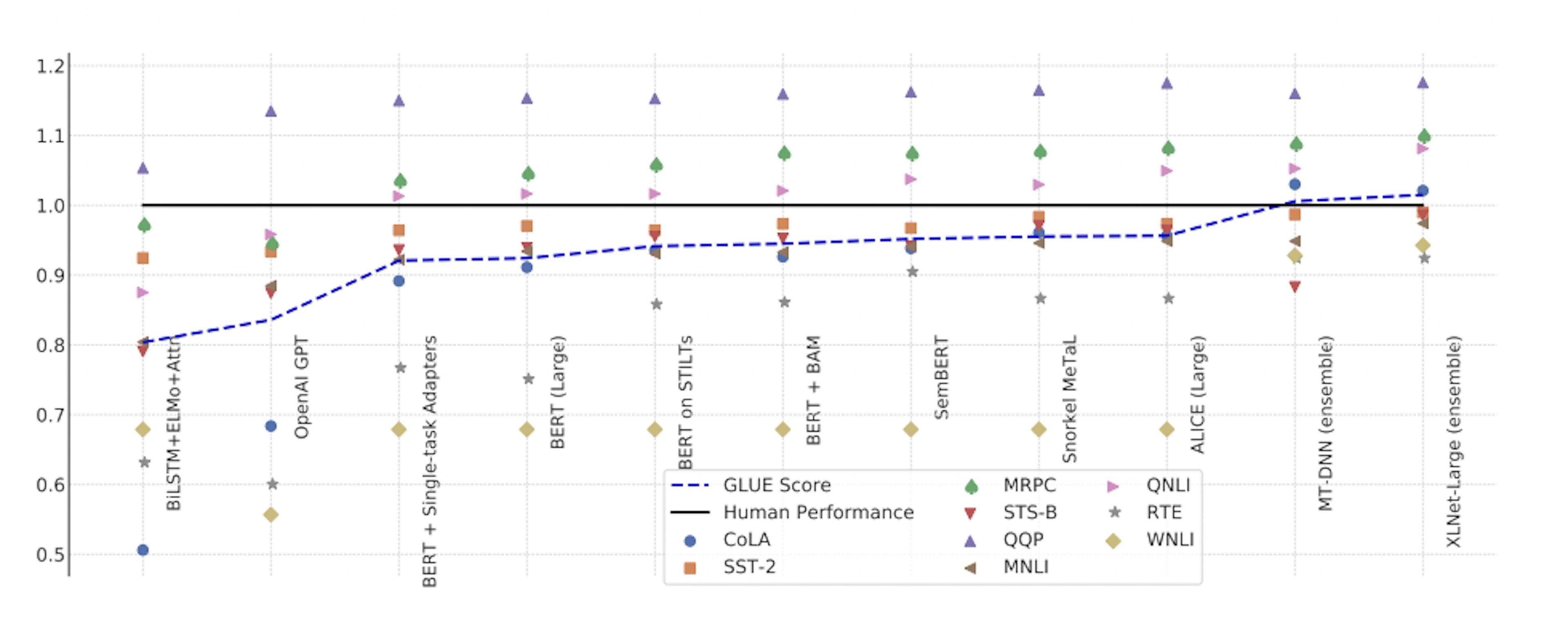
GLUE benchmark performance for submitted systems, rescaled to set human performance to 1.0 (Source: Wang et al.)
GLUE benchmark performance for submitted systems, rescaled to set human performance to 1.0 (Source: Wang et al.)
The collection of GLUE benchmarks calculates the model's performance across an assorted range of metrics, deriving the final score as an average from all these tasks. It should be noted that both the GLUE and SuperGLUE benchmarks are based on the same principle. In this article, our primary focus is on SuperGLUE, given its superior sophistication and broader acceptance. More precisely, SuperGLUE enhances the GLUE benchmark in the following ways:
More challenging tasks: The SuperGLUE benchmark only retained 2 out of 9 tasks in the GLUE benchmark, while the rest was gathered from public proposals and selected based on difficulty.
More diverse task formats: Besides sentence and sentence-pair classification tasks, SuperGLUE includes coreference resolution and question-answering tasks.
Comprehensive human baselines: All benchmark subtasks include human baselines for comparison.
Improved code support: SuperGLUE is shipped with a modular package that allows researchers to submit to the leaderboard with ease
Refined usage rules: The SuperGLUE leaderboard has been revamped regarding fairness, information, and credits to the authors.
The tasks in SuperGLUE are designed to be solvable by an English-speaking college student but surpass what current (late 2019) language models can accomplish. The tasks also exclude domain knowledge, meaning the model is tested only on its language understanding, not its extent of knowledge.
The subtasks included in SuperGLUE are the following:
Boolean Questions: BoolQ is a question-answering task. It consists of a short passage from a Wikipedia article and a yes/no question about the model. The performance is evaluated with accuracy.
CommitmentBank: CB consists of short texts containing at least one embedded clause. The task involves determining the writer's commitment level to the truth of the clause. The data is obtained from various sources such as the Wall Street Journal, the British National Corpus, and Switchboard. Given the data imbalance, accuracy and the unweighted average F1 score are used for evaluation.
Choice of Plausible Alternatives: COPA is a causal reasoning task. The system is presented with a sentence and must discern the cause or effect from two options. The examples are carefully curated from blog posts and a photography encyclopedia. The evaluation metric is accuracy.
Multi-Sentence Reading Comprehension: MultiRC is a QA task involving a context paragraph, a related question, and multiple potential answers. The system must classify the answers as true or false. The evaluation metrics include an F1 score over all answer options and an exact match of each question's answer set.
Reading Comprehension with Commonsense Reasoning Dataset: ReCoRD is a multiple-choice QA task involving a news article and a question with a masked entity. The system must predict the masked entity from provided options. Evaluation involves calculating the max token-level F1 score and exact match.
Recognizing Textual Entailment: RTE datasets are from annual competitions on textual entailment. The data from several iterations of the competition is merged into a two-class classification task: entailment and not_entailment. The evaluation metric is accuracy.
Word-in-Context: WiC is a binary classification task involving sentence pairs and a polysemous word. The task is determining if the word has the same sense in both sentences. The evaluation metric used is accuracy.
Winograd Schema Challenge: The WSC is a task in coreference resolution that requires identifying the correct referent of a pronoun from a list of noun phrases in the sentence. The task necessitates the use of commonsense reasoning and is evaluated using accuracy.

Examples of each of the SuperGLUE subtasks (Source: Wang et al.)
Examples of each of the SuperGLUE subtasks (Source: Wang et al.)
In addition to the eight subtasks, two more "metrics" analyze the model at a broader scale.
Broad Coverage Diagnostics: This includes experts' diagnostic datasets to automatically test models against various linguistic, common sense, and worldly knowledge. Each sample in this dataset consists of a pair of sentences marked with a three-way entailment relation (entailment, neutral, or contradiction). The relationship between these sentences is further tagged with labels to identify the linguistic phenomena defining their connection. In SuperGLUE, the contradiction and neutral labels are collapsed into a single 'not_entailment' label. Predictions on this dataset, using the model used for the Recognizing Textual Entailment (RTE) task, are required for submissions. To gauge human performance, non-expert annotations are collected. The estimated human performance accuracy is 88%, with a [Matthew’s correlation coefficient](https://en.wikipedia.org/wiki/Phi_coefficient) (MCC) of 0.77.
Analyzing Gender Bias in Models: This analytical tool detects social biases in machine learning models. A diagnostic dataset, Winogender, has been included to measure gender bias in coreference resolution systems. Each sample in Winogender consists of a premise sentence with a male or female pronoun and a hypothesis offering a potential antecedent of the pronoun. Performance on Winogender is evaluated using accuracy and the gender parity score: the percentage of minimal pairs for which the predictions are the same. A perfect gender parity score can be easily obtained by guessing the same class for all examples; hence a high gender parity score is only significant if paired with high accuracy. Despite its limitations, such as lack of coverage for all forms of social bias or gender, Winogender provides a general understanding of how social biases evolve with model performance. Human performance is estimated to be an accuracy of 99.7% and a gender parity score of 0.99.
The final SuperGLUE benchmark score is computed as the simple average across all tasks.
Closing Remarks
Unlike the HuggingFace leaderboard for LLMs, the leaderboard for SuperGLUE is populated mainly by models developed by smaller research labs rather than well-known close-sourced models such as Claude and GPT.
Instead of different single models, there tend to be submissions that include variations of already well-known models such as GPT, BERT, and RoBERTa.
As we progress, we anticipate new models will be evaluated on SuperGLUE, although it will not stand up to the frequent updates of the HuggingFace leaderboards. But the contributions of the benchmark ensure LLMs' evolving capabilities are thoroughly and justly tested. Ultimately, the goal remains not just to build models that can excel on a language understanding benchmark but to ensure minimal bias and unfairness.



