Data Poisoning
Join us as we discuss the intricacies of data poisoning in machine learning, uncovering its mechanisms, impacts, and the urgent need for robust defense strategies.
At the heart of every AI and ML model lies the bedrock of data integrity, critical for their operations and decision-making processes. Yet, data poisoning acts as a silent saboteur, undermining this integrity and manipulating outcomes. It's a stark reminder that in the rapidly evolving landscape of AI and ML applications, the stakes have never been higher.
What sets data poisoning apart from other cyberattacks, and why are machine learning models particularly vulnerable? How does this threat manifest in real-world scenarios, and what are the challenges in mitigating its effects? Join us as we discuss the intricacies of data poisoning in machine learning, uncovering its mechanisms, impacts, and the urgent need for robust defense strategies.
What is Data Poisoning in Machine Learning
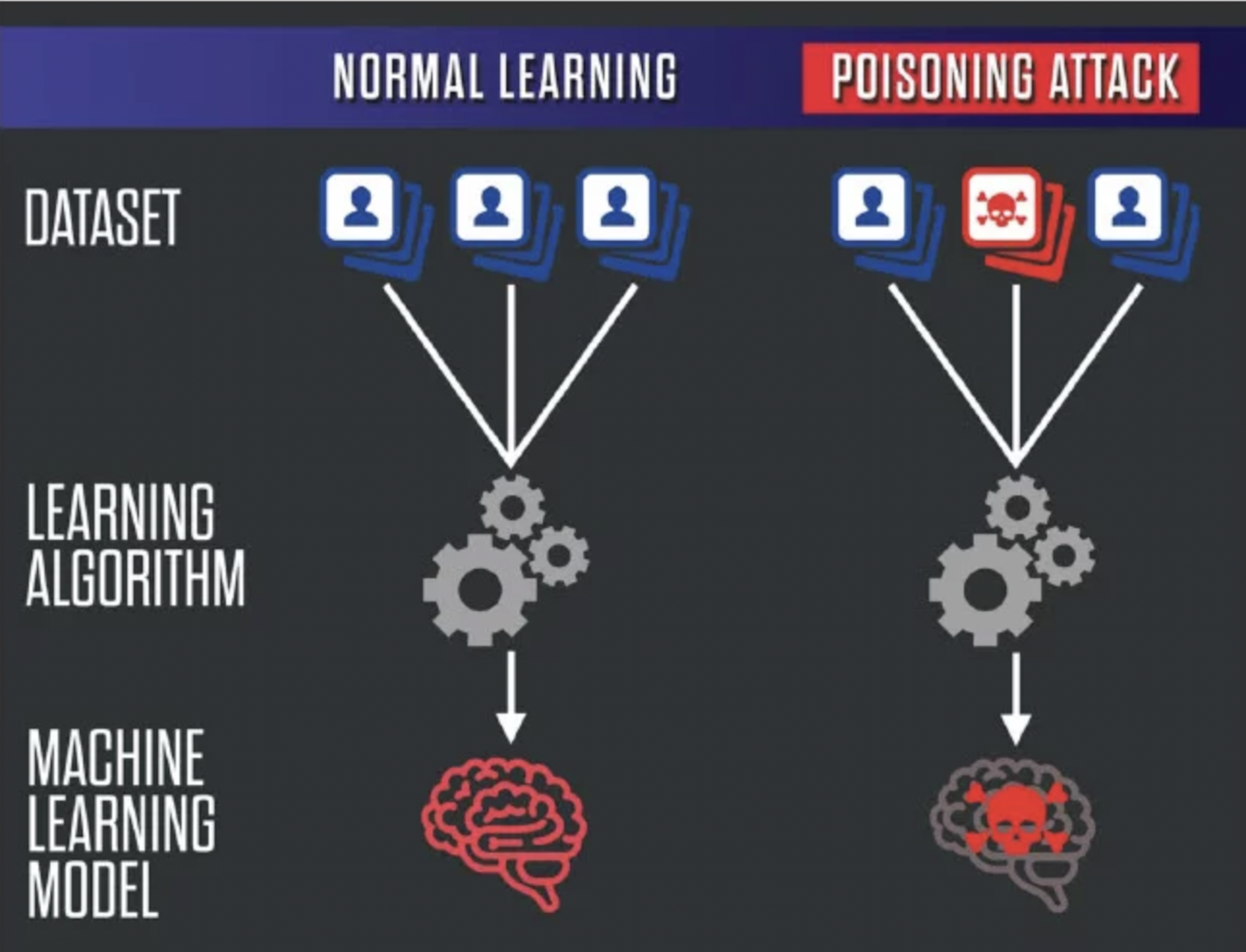
Source: from Comiter, 2019
Data poisoning represents a cyberattack strategy where adversaries intentionally compromise the training data of an AI or ML model. The aim is simple yet devastating: manipulate the model's operations to serve the attacker's ends. This attack not only questions the reliability of AI-driven decisions but also poses a significant threat to the foundational integrity upon which machine learning models operate. Unlike generic cyberattacks that target networks or systems broadly, data poisoning zeroes in on the lifeblood of machine learning—its data.
Operational Influence of Compromised Datasets: As CrowdStrike eloquently explains, the operational influence of compromised datasets in machine learning can be profound. From subtle misclassifications to drastic shifts in decision-making, the ramifications extend far beyond the digital realm.
The Vulnerability of Machine Learning Models: The very strength of machine learning—its reliance on extensive datasets for training—becomes its Achilles' heel in the face of data poisoning. The larger the dataset, the more challenging it is to ensure each data point's integrity. This complexity, coupled with the subtle nature of dataset manipulations, makes detecting and mitigating data poisoning particularly arduous.
Real-life Implications: The implications of data poisoning stretch across various sectors, from autonomous vehicles misinterpreting road signs to financial systems making erroneous decisions. The potential for harm in automated systems, which increasingly rely on AI and ML for decision-making, underscores the urgency of addressing this threat.
The Challenge of Detection and Mitigation: One of the most daunting aspects of data poisoning is the subtlety with which data can be manipulated. Detecting these manipulations requires not only sophisticated algorithms but also a nuanced understanding of the model's expected behavior. Moreover, the iterative nature of these attacks, where adversaries refine their approach based on the model's responses, adds another layer of complexity to defense efforts.
The growing dependence on AI and ML across sectors only amplifies the relevance of data poisoning. As we venture further into this AI-driven era, recognizing and fortifying against such attacks becomes paramount. The journey to secure the integrity of machine learning models from data poisoning is fraught with challenges, but it is a necessary endeavor to ensure the reliability and safety of AI applications.
How Data Poisoning Works
The concept of data poisoning in machine learning isn't just theoretical; it's a practical concern that can have tangible, sometimes hazardous outcomes. This becomes particularly alarming in systems where life or safety is at stake, such as in self-driving car technologies. Let's dissect the mechanics behind this form of cyberattack, highlighting the blend of sophistication and subterfuge that makes it so perilous.
Injecting Poisoned Data into Training Sets
Imagine a scenario where a self-driving car misinterprets road signs due to compromised training data, as highlighted by defence.ai. This isn't science fiction but a stark reality of data poisoning. Attackers meticulously introduce malicious data into a model's training set, aiming to skew its learning process. This malicious data is designed to look genuine, making it a Trojan horse within the dataset. The goal? To deceive the model into making incorrect predictions or decisions—like mistaking a stop sign for a speed limit sign, with potentially disastrous outcomes.
Blending Poisoned Data with Legitimate Data
Attackers employ a cunning tactic of blending poisoned data with legitimate data to escape detection. This process is akin to a needle in a haystack, where the needle is the poisoned data. By ensuring that the malicious data mimics the characteristics of legitimate data, attackers increase the likelihood of their data being used in the model's training process. This subtlety is what makes detecting and removing poisoned data so challenging.
'Backdoor' Attacks
Backdoor attacks represent a sinister evolution in data poisoning strategies. Here, attackers create conditions under which the AI model behaves normally for the most part but activates malicious behavior in response to specific, carefully crafted inputs. This could mean a self-driving car functions correctly under normal conditions but fails to stop at a stop sign if certain conditions are met, such as a specific sticker being present on the sign.
Sophisticated Algorithms and Social Engineering
The creation of poisoned data isn't left to chance. Attackers use sophisticated algorithms to generate data that appears benign to developers and security systems. Moreover, through social engineering techniques like phishing attacks, adversaries gain access to data repositories, further facilitating the introduction of poisoned data. This underscores the importance of robust security measures and constant vigilance in protecting data sources.
The Iterative Nature of Attacks
Data poisoning isn't a set-it-and-forget-it type of attack. Instead, attackers engage in an iterative process, continuously refining their poisoned data based on the model's responses. This ongoing adjustment ensures that their attacks remain effective even as models evolve and developers attempt to mitigate threats. It's a game of cat and mouse, where the stakes involve the integrity of AI systems.
The Importance of Data Provenance and Integrity Checks
Given the stealthy nature of data poisoning, ensuring the provenance and conducting integrity checks of training data becomes paramount. Identifying the source of each data point and verifying its authenticity can help in isolating and eliminating poisoned data. However, this requires a comprehensive understanding of the data's lifecycle and the implementation of stringent data management practices.
Psychological and Operational Challenges
Accepting the possibility of data poisoning requires a paradigm shift in how organizations view their AI and ML systems. The acknowledgment that these systems can be compromised is the first step towards developing effective countermeasures. This involves not only technical solutions but also addressing the psychological resistance to acknowledging vulnerabilities within systems heavily invested in both financially and operationally.
As we traverse the landscape of AI and machine learning, the specter of data poisoning looms large, challenging us to fortify our defenses and remain ever vigilant. The complexity of these attacks, coupled with the subtlety of their execution, underscores the critical need for a multifaceted approach to AI security—one that encompasses technological, procedural, and psychological dimensions.
Types of Data Poisoning Attacks
In the realm of machine learning, the integrity of training data is paramount. Unfortunately, this data can fall victim to various types of attacks, each with its own unique mechanism and detrimental effects. As identified in a comprehensive breakdown by fedtechmagazine, these attacks can be classified into availability attacks, targeted attacks, subpopulation attacks, and indiscriminate attacks. Understanding these can help in devising more effective defenses against data poisoning.
Availability Attacks
Definition: These attacks aim to compromise the overall performance of a machine learning model, making it unreliable across a broad spectrum of tasks.
Methodology: By flooding the training data with misleading information, attackers cause the model to make errors indiscriminately, lowering its utility and reliability.
Example: Injecting false data into a spam detection system, causing it to misclassify legitimate emails as spam and vice versa.
Impact: Such attacks can significantly degrade the user experience and trust in automated systems, especially in sectors where precision is critical, like finance and email filtering services.
Targeted Attacks
Definition: Targeted attacks are more sophisticated, aiming to alter a model's behavior under specific conditions without affecting its general performance.
Methodology: Attackers insert data designed to trigger the desired misbehavior only in specific scenarios, making these alterations difficult to detect during routine evaluations.
Example: Modifying a facial recognition system to misidentify or fail to recognize a particular individual's face.
Impact: These attacks can have serious implications for security systems, personal identification processes, and any sector relying on precise identification or authentication mechanisms.
Subpopulation Attacks
Definition: These attacks focus on influencing the model's behavior concerning a particular segment of the input space, targeting a specific subgroup of data.
Methodology: Poisoned data is crafted to affect the model's decisions for a certain subpopulation, leaving the rest of the model's performance unaffected.
Example: Altering a credit scoring model to unfairly rate individuals from a specific demographic as high risk.
Impact: Subpopulation attacks can lead to biased outcomes, affecting fairness and equity in services like loan approvals, insurance rates, and healthcare provisions.
Indiscriminate Attacks
Definition: These aim to corrupt the model's output across a wide range of inputs, without targeting any specific outcome or subgroup.
Methodology: Attackers flood the training set with randomly generated or significantly distorted data points, aiming to reduce the overall accuracy of the model.
Example: Disrupting the accuracy of a weather prediction model by inputting incorrect temperature and humidity readings.
Impact: Indiscriminate attacks can have a broad impact, affecting decisions and predictions in various sectors like agriculture, environmental planning, and emergency response systems.
Each type of data poisoning attack requires a strategic approach from attackers, depending on their resources and objectives. The choice of attack also reflects the sector or application they aim to disrupt. From finance, where availability attacks could undermine the reliability of trading algorithms, to healthcare, where subpopulation attacks might skew diagnostic AI, the implications are vast and varied. In autonomous vehicles, targeted attacks could compromise safety systems, while indiscriminate attacks could disrupt logistics and fleet management systems across the board. Understanding these attack vectors is crucial for developing robust defenses and ensuring the continued reliability and trustworthiness of machine learning applications in our increasingly automated world.
Impact of Data Poisoning on AI Security
Immediate Effects on Machine Learning Model Integrity
Data poisoning directly undermines the integrity and reliability of machine learning (ML) models. By contaminating the training data, adversaries can significantly alter the decision-making processes of AI systems. This manipulation leads to:
Erroneous Outputs: The contaminated data skews the AI's learning process, resulting in flawed outputs and decisions.
Decreased Model Reliability: The accuracy and reliability of the AI system plummet, making it untrustworthy for critical decision-making tasks.
Increased Vulnerability: Poisoned models become more susceptible to further attacks and manipulations, compounding the security risks.
Long-term Consequences on Trust and Infrastructure
The ramifications of data poisoning extend far beyond immediate disruptions, eroding trust in AI systems and posing risks to critical infrastructure. Noteworthy points include:
Eroded User and Developer Trust: Confidence in AI decision-making and reliability diminishes, impacting future adoption and investment in AI technologies.
Infrastructure Risks: The zdnet.com reference to the watering hole attack on a water infrastructure construction company site exemplifies how critical systems can be compromised, endangering public safety and security.
Misuse in Political and Information Campaigns: Data poisoning can be weaponized to manipulate public opinion, interfere in elections, or propagate misinformation, undermining democratic processes and societal trust.
Economic Impacts and The Cost of Mitigation
The financial implications of data poisoning are profound, affecting both the immediate costs of mitigation and the broader economic landscape. Key impacts include:
Mitigation Expenses: Identifying, rectifying, and safeguarding against data poisoning require significant investments in technology and expertise.
Operational Disruptions: Compromised decision-making can lead to operational inefficiencies, lost revenue, and damaged reputations.
Innovation Stifling: The fear of data poisoning could deter investment in AI research and development, slowing innovation and economic growth.
Balancing Data Openness with Security
In an era where data is the new oil, balancing openness with security becomes a paramount challenge, especially in collaborative AI projects. This balance entails:
Openness vs. Security: While data sharing accelerates innovation, it also increases the risk of poisoning. Finding the middle ground is crucial for advancing AI while safeguarding against attacks.
Collaborative Efforts: Sharing strategies, tools, and best practices among stakeholders can help in fortifying defenses against data poisoning across the board.
The Role of AI Ethics
Ethical considerations play a critical role in combating data poisoning, guiding the development and deployment of AI systems. Important aspects include:
Developing Ethical Guidelines: Establishing robust ethical frameworks can help in preemptively identifying and mitigating potential abuses of AI, including data poisoning.
Promoting Transparency and Accountability: Ensuring that AI systems are transparent in their decision-making processes and that developers are accountable for the integrity of their models is essential in maintaining trust.
The multifaceted impacts of data poisoning in machine learning underscore the importance of vigilance, collaboration, and ethical considerations in securing AI systems against this evolving threat. As AI continues to permeate various sectors, the collective efforts of developers, users, and policymakers will be crucial in safeguarding the integrity and reliability of these transformative technologies.
Defending Against Data Poisoning
The escalating sophistication of data poisoning in machine learning mandates a robust defense mechanism. Here’s a strategic approach to safeguard AI and ML systems against these nuanced threats.
Model Monitoring, Routine Data Validation, and Anomaly Detection
To fortify defenses against data poisoning, implementing a trio of strategies—model monitoring, routine data validation, and anomaly detection—becomes indispensable.
Model Monitoring: Continuously observe the performance of AI models to identify any deviations from expected behavior, which may indicate the presence of poisoned data.
Routine Data Validation: Regularly validate training datasets for accuracy and integrity to ensure they haven’t been tampered with.
Anomaly Detection: Employ state-of-the-art anomaly detection algorithms to spot unusual patterns or data points that could signify a poisoning attempt.
The Role of Data Provenance
Understanding the origin of data (data provenance) is crucial in confirming its integrity.
Traceability: Ensure every piece of data can be traced back to its source, enabling the identification of potential points of compromise.
Integrity Checks: Implement mechanisms to verify data integrity at every stage of its lifecycle, from collection to processing.
Secure Data Collection Processes
To preempt the risk of data poisoning, secure data collection and vetting of data sources are critical.
Vetting Data Sources: Rigorously assess the credibility of data sources before incorporating their data into training datasets.
Encryption and Access Control: Protect data during collection and storage with encryption and strict access controls to prevent unauthorized tampering.
AI Models Capable of Detecting and Resisting Data Poisoning
The development of resilient AI models is a forward-thinking strategy to counter data poisoning.
Adversarial Training: Incorporate adversarial examples in the training phase to enhance the model’s resistance to poisoned data.
Dynamic Learning Algorithms: Implement algorithms that can dynamically adjust when poisoned data is detected, mitigating its impact.
Ongoing Security Training for AI Developers and Data Scientists
Educating AI practitioners about the nuances of data poisoning and its prevention is a foundational step.
Regular Workshops: Conduct workshops and training sessions on the latest data poisoning tactics and countermeasures.
Security Awareness: Foster a culture of security mindfulness, emphasizing the critical role of data integrity in AI/ML projects.
Potential of Blockchain and Decentralized Technologies
Blockchain and other decentralized technologies offer promising avenues for securing data against poisoning.
Immutable Records: Leverage blockchain’s immutable ledger to guarantee data integrity, making unauthorized alterations easily detectable.
Decentralized Data Storage: Utilize decentralized storage solutions to reduce the risk of centralized data breaches that could lead to poisoning.
Collaborative Efforts for AI Security Standards
The fight against data poisoning requires a united front, with academia, industry, and government playing pivotal roles.
Standard Development: Collaboratively develop and adopt standards for data integrity and security in AI applications.
Shared Knowledge Base: Create a shared repository of known data poisoning techniques and countermeasures to benefit the broader AI community.
Regulatory Frameworks: Work towards establishing regulatory frameworks that mandate stringent data security and integrity measures.
In conclusion, defending against data poisoning in machine learning necessitates a multi-faceted approach that combines technological solutions with human expertise and collaborative efforts. By implementing these best practices, the AI community can significantly enhance the resilience of machine learning models against the evolving threat of data poisoning.