The Pile
This article delves into the essence of the Pile Dataset, unraveling its creation, significance, and the unparalleled advantage it offers to the AI community.
In the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML), data is king. But not just any data—the diversity, quality, and scale of the training datasets can significantly influence the capabilities of large language models (LLMs). With this in mind, have you ever wondered what powers the AI systems that understand and generate human-like text? Enter the Pile Dataset, a cornerstone in the development of sophisticated AI technologies. Created by EleutherAI in 2020, this dataset has reshaped the boundaries of what's possible in AI research and development. This article delves into the essence of the Pile Dataset, unraveling its creation, significance, and the unparalleled advantage it offers to the AI community. Are you ready to unlock the secrets behind one of the most comprehensive training datasets for LLMs?
Section 1: What is The Pile?
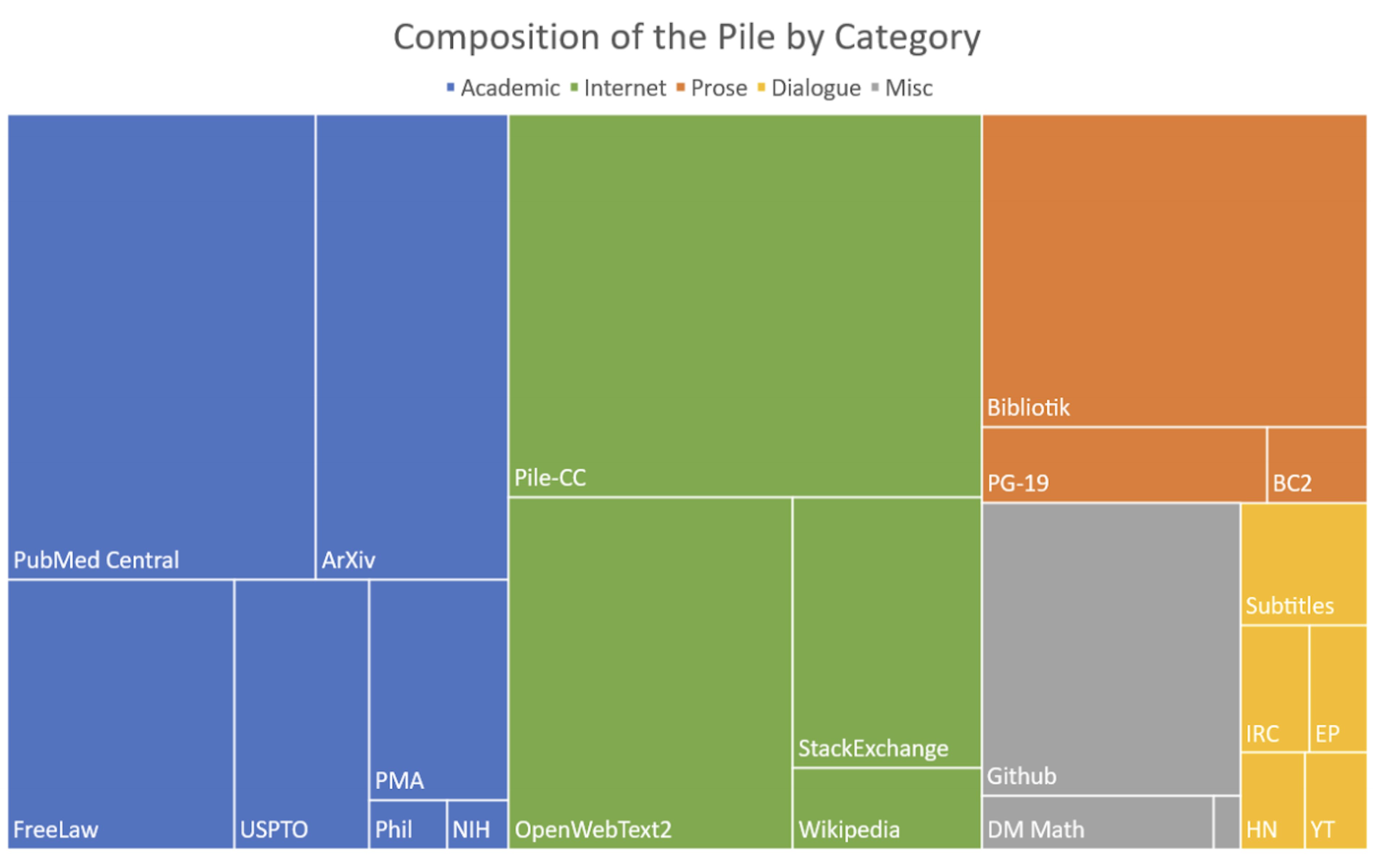
The Pile Dataset stands as a monumental achievement in the field of artificial intelligence and machine learning, heralding a new era of innovation and knowledge discovery. Crafted with meticulous attention by EleutherAI, its emergence in 2020 marked a significant leap forward, offering a treasure trove of data meticulously curated to train large language models (LLMs) with unprecedented efficiency and depth.
Upon its release to the public on December 31, 2020, the Pile Dataset instantly became a beacon for researchers and developers worldwide, embodying the spirit of open-source collaboration. Its sheer size—reported variably as 886.03 GB and 825 GiB across sources—underscores the ambition behind its creation. Yet, it's the dataset's composition that truly sets it apart: an amalgamation of 22 smaller, high-quality datasets, including 14 novel datasets specifically crafted for inclusion in the Pile.
Diversity is at the heart of the Pile Dataset. Its architects gathered data from a wide array of sources, ensuring a broad spectrum of text types and topics. This diversity is not just a hallmark of quality but a strategic element designed to enhance the training of LLMs, making them more adaptable, nuanced, and capable of understanding and generating a variety of texts.
The objectives behind creating the Pile Dataset were clear: to provide a more diverse and comprehensive resource for training LLMs than ever before. The selection criteria for the datasets included in the Pile were rigorous, focusing on the quality and diversity of data. The challenges of compiling such a vast and varied dataset were immense, yet the result is a resource that significantly advances the capabilities of language models.
Comparing the Pile Dataset to other datasets like Common Crawl reveals its unique value proposition. While Common Crawl offers a massive collection of web pages for training LLMs, the Pile Dataset's curated, high-quality composition ensures it provides a more targeted, effective training experience. This distinction underscores the Pile Dataset's significance in the ongoing development of language models, propelling the field toward more sophisticated, nuanced AI technologies.
In embracing the open-source ethos, the Pile Dataset embodies the collective aspiration of the AI community to foster innovation and progress. Its availability to researchers and developers around the globe is not just a gesture of goodwill but a strategic move to accelerate advancements in AI and machine learning, making the Pile Dataset a cornerstone of modern AI research.
How is The Pile used?
The Pile Dataset serves as a foundational element in the training and development of large language models (LLMs), revolutionizing the way machines understand and generate human-like text. Its extensive use by EleutherAI, among other research organizations, marks a significant milestone in AI development, showcasing the dataset's versatility and robustness. Here's a deep dive into the multifaceted applications of the Pile Dataset:
Integrating the Pile Dataset into LLM Training
Preprocessing Steps: Before integration, the Pile Dataset undergoes meticulous preprocessing to ensure compatibility with LLMs. This may include tokenization, normalization, and cleaning to remove any inconsistencies or irrelevant information.
Complementing Other Datasets: The Pile complements existing datasets by filling gaps in data diversity and quality, offering a broader context and more varied linguistic patterns for LLMs to learn from.
Training Regimen: It's seamlessly woven into the training regimen of LLMs, often combined with dynamic learning rates and advanced optimization strategies to maximize learning efficiency.
Impact on Language Model Performance
Enhanced Understanding: The Pile Dataset has been instrumental in enhancing LLMs' understanding of complex language nuances, significantly improving their ability to comprehend and generate text.
Notable Improvements: Studies and experiments leveraging the Pile Dataset have reported marked improvements in model accuracy, fluency, and contextual relevance, showcasing its effectiveness in elevating model performance.
Role in Academic Research
Exploring New AI Theories: The Pile Dataset provides a rich resource for academic researchers to test hypotheses, explore new AI theories, and push the boundaries of what's possible in language processing.
Improving Existing Algorithms: It also plays a critical role in refining and improving existing algorithms, offering a diverse testing ground to identify and overcome model limitations.
Contribution to Sophisticated Language Models
Broader Range of Tasks: The diversity and quality of the Pile Dataset enable the development of more sophisticated language models, capable of handling a wider array of tasks, from complex text generation to nuanced question-answering systems.
Nuanced Understanding: By exposing models to a wide variety of linguistic structures and themes, the Pile Dataset facilitates a deeper, more nuanced understanding of language.
Future Applications and Emerging Fields
Beyond Current Use: The potential applications of the Pile Dataset extend far beyond its current use, promising to play a pivotal role in emerging AI technologies and fields, such as predictive AI and cognitive computing.
Enabling Innovation: By serving as a comprehensive training tool, the Pile Dataset lays the groundwork for future breakthroughs in AI, opening new avenues for exploration and innovation.
Challenges and Considerations
Computational Requirements: The vast size and complexity of the Pile Dataset pose significant computational challenges, requiring substantial resources for efficient processing and training.
Ethical Considerations: The diverse sources of data included in the Pile Dataset necessitate careful consideration of ethical implications, ensuring the responsible use of data and the prevention of bias in trained models.
The Pile Dataset represents a monumental leap forward in the quest for more intelligent, capable, and efficient language models. By providing an unparalleled resource for training and research, it not only enhances the current capabilities of LLMs but also paves the way for future advancements in AI. As we continue to explore the depths of natural language understanding and generation, the Pile Dataset stands as a testament to the power of collaboration, innovation, and the relentless pursuit of knowledge in the AI community.