k-Shingles
Have you ever pondered how search engines identify similar content, or how plagiarism detectors work their magic? At the heart of these technologies lies a fascinating concept: Jaccard Similarity and k-Shingles.
Have you ever pondered how search engines identify similar content, or how plagiarism detectors work their magic? At the heart of these technologies lies a fascinating concept: Jaccard Similarity and k-Shingles. Imagine you have two sets of data, and you wish to know how closely they resemble each other. This is where Jaccard Similarity, a statistical measure, comes into play, offering a mathematical approach to understanding similarity and diversity. Now, couple that with k-Shingles, a technique in text mining that transforms chunks of text into comparable sets. The blend of these two methodologies provides a powerful tool for various applications, from SEO to bioinformatics.
Section 1: What is Jaccard Similarity and k-Shingles?
The Jaccard similarity of sets S and T is |S ∩ T| / |S ∪ T|, that is, the ratio of the size of the intersection of S and T to the size of their union. You can denote the Jaccard similarity of S and T by sim(S, T).
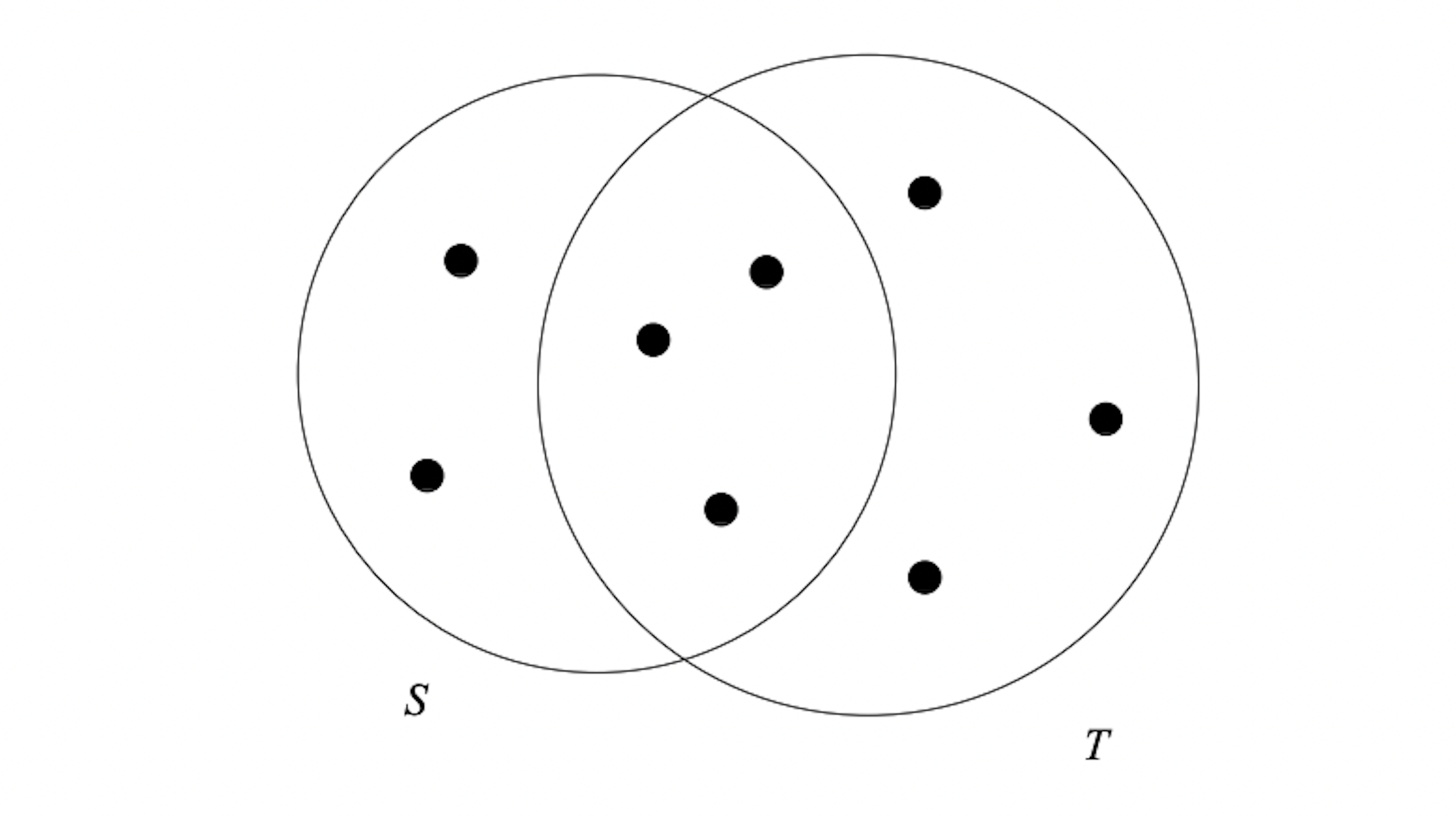
These two sets have a Jaccard Similarity of 3 / 8. (Source: mmds.org)
Jaccard Similarity represents a statistical measure for evaluating the likeness and diversity among sample sets. It is a concept named after botanist Paul Jaccard, who introduced this measure in the early 20th century to compare biological species. This index takes values ranging from 0 to 1, where 0 signifies no similarity and 1 denotes identical sets.
k-Shingles, or k-grams, are integral to text mining. They transform text into set representations for comparison, where 'k' determines the length of each shingle. For instance, a 3-shingle of the word 'analytics' would produce the subsets 'ana', 'nal', 'aly', ‘lyt’, and so forth.
The development of the Jaccard Similarity Index laid the groundwork for comparing complex data sets in numerous fields. It's vital to understand that the choice of 'k' in k-shingles affects the granularity of comparison; larger values of 'k' will yield more precise comparisons but may also increase computational complexity.
In the context of text processing, shingling allows us to break down documents into smaller segments, creating subsets of tokens. These subsets can then be compared for similarity using the Jaccard Similarity Index. As the size of 'k' increases, the comparison becomes more stringent, potentially missing broader similarities that a smaller 'k' might catch.
The significance of a 'good' Jaccard similarity score is somewhat subjective and context-dependent. Some agree that scores above 0.7 typically suggest high similarity. However, what is considered high can vary based on the application.
Computational considerations are crucial when applying Jaccard Similarity and k-Shingles, especially regarding the dimensionality of large text corpuses. High dimensionality can lead to increased computational resources and processing time.
Let's consider an example: we have two strings of text, "the quick brown fox" and "the quick brown fox jumps". If we choose k=3 for our shingles, the first string will produce shingles like "the", "he ", " qu", and so on. Note that the space is counted as a character, just as the letters are.
The second string will have all these plus " ju", "jum", "ump", and “mps”. Calculating Jaccard Similarity involves counting the unique shingles in both sets (the union) and those shared by both (the intersection), then dividing the size of the intersection by the size of the union. This calculation will yield a value between 0 and 1, quantifying the similarity of the two text strings based on the chosen shingle length.
Section 2: Mathematics of Jaccard Similarity and k-Shingles
The Jaccard Similarity Index is the cornerstone of comparing sample sets, and its formula is elegantly simple. To calculate it, one divides the number of elements in the intersection of two sets by the number of elements in their union. This yields a score between 0 and 1, reflecting the degree of similarity; a score of 1 signifies identical sets, while a score of 0 indicates no common elements.
Binary Representation of k-Shingles
Each k-shingle can be represented in a binary form within a characteristic matrix.
Rows typically represent the shingles, while columns stand for the documents.
A '1' denotes the presence of a shingle in a document, while a '0' indicates its absence.
This binary matrix aids in the swift computation of similarities, as intersection and union operations transform into simple arithmetic on binary values.
Probability Theory and Minhashing
Minhashing serves as a probabilistic method for estimating the Jaccard Similarity.
According to the probability theory detailed in the Stanford infolab source, the probability that a minhash function will equal the Jaccard Similarity of two sets is strikingly high.
This relationship is crucial as it allows for the approximation of similarity without direct computation over potentially large sets, thus optimizing the process.
Visualizing with Venn Diagrams
Venn diagrams offer a visual representation of Jaccard Similarity, as illustrated in this Medium article.
The intersection (often shaded) represents the common elements, while the union encapsulates all elements from both sets.
These diagrams make the concept more accessible by providing an intuitive grasp of the overlap between sets.
The Shingle Inequality Phenomenon
A longer shingle does not guarantee a higher Jaccard similarity; this is known as 'shingle inequality.'
For instance, a 5-shingle analysis might yield a lower similarity score than a 3-shingle analysis for the same text sets due to its increased specificity.
This phenomenon underscores the importance of choosing an appropriate 'k' value based on the desired level of detail in the analysis.
Converting Text Documents into k-Shingles
The process begins by selecting a 'k' value and then breaking the text into overlapping chunks of length 'k.'
These chunks are then hashed to create a set of unique identifiers, reducing the space needed to store the shingles.
Impact of 'k' Value on Computational Complexity and Sensitivity
A smaller 'k' leads to a larger number of shingles, increasing the computational load but potentially capturing more nuanced similarities.
Conversely, a larger 'k' creates fewer, more distinct shingles, which may overlook subtle similarities but provide a more computationally efficient analysis.
The choice of 'k' thus involves a trade-off between computational complexity and the sensitivity of the similarity detection.
In practice, applying the principles of Jaccard Similarity and k-Shingles requires a careful balance. Understanding the mathematical underpinnings enables one to fine-tune the analysis, whether it be for detecting plagiarism, designing recommendation systems, or analyzing biological sequences. Selecting the right 'k' value, understanding the computational trade-offs, and interpreting the similarity scores all play pivotal roles in leveraging this powerful toolset effectively.
Section 3: Use cases of Jaccard Similarity and k-Shingles
Jaccard Similarity and k-Shingles, with their robust analytical capabilities, serve a multitude of applications across diverse fields. These tools not only enhance our understanding of textual data but also streamline the detection of similarities and variances in data sets.
Plagiarism Detection
In academia and publishing, ensuring the originality of content is paramount. Jaccard Similarity offers a precise method for comparing sets of k-shingles across documents to unearth instances of content replication.
As each document transforms into a unique set of k-shingles, comparing these sets highlights overlapping shingles, flagging potential plagiarism.
This technique proves especially vital in identifying not just direct copying but also more subtle instances where sentence structures or phrases may be rephrased.
Recommendation Systems
E-commerce platforms and content providers rely on recommendation systems to personalize user experiences. Here, Jaccard Similarity informs the clustering of items or users by analyzing the likeness in their attributes or behaviors.
By generating k-shingles from user activity or product characteristics, platforms can swiftly pair users with products, services, or other users that share a high Jaccard score, indicating similar interests or preferences.
Search Engine Optimization
In the digital marketing realm, content uniqueness significantly impacts search engine rankings. Web pages undergo analysis for duplicate content using k-shingles, ensuring that each page offers distinct and valuable information.
Search engines leverage Jaccard Similarity to identify and penalize websites that display a high degree of similarity to existing content, thereby encouraging the creation of unique, quality content.
Biological Data Analysis
The analysis of genetic sequences mirrors the comparison of textual data in many ways. Utilizing research from arXiv, scientists compare sequences by converting them into k-shingles, then applying Jaccard Similarity to detect commonalities or mutations.
This approach facilitates the study of evolutionary relationships and the identification of genetic markers associated with diseases.
Natural Language Processing (NLP)
NLP tasks such as topic modeling and text summarization benefit greatly from Jaccard Similarity and k-Shingles. These tools aid in distilling large volumes of text into coherent themes or summaries by recognizing patterns in the data.
By breaking down text into k-shingles, models can identify and group together documents that share thematic similarities, enhancing the quality of information extraction.
Machine Learning Workflows
In feature engineering, the integration of Jaccard Similarity and k-Shingles allows for the creation of new features that capture textual similarities, which can serve as inputs for machine learning algorithms.
This process often involves transforming text into numerical values based on their Jaccard scores, which can then be used to train models with a higher degree of accuracy.
Social Network Analysis
Jaccard Similarity lends itself to the analysis of social networks by helping to identify community structures. By examining shared attributes among users, represented as k-shingles, networks can discern tightly-knit communities or potential connections.
This method is vital for platforms seeking to enhance user engagement by suggesting relevant connections or content based on shared interests and behaviors.
The versatility of Jaccard Similarity and k-Shingles is evident through their wide-ranging applications. From safeguarding intellectual property to personalizing user experiences, and from advancing genetic research to refining machine learning models, these techniques are integral to modern data analysis. As data continues to grow in volume and complexity, the adoption of these methods becomes even more crucial for extracting valuable insights and fostering innovation across industries.